TICK stack でモニタリング環境を構築 (Telegraf + InfluxDB + Chronograf + Kapacitor)

概要
TICK stack とやらを最低限の設定で構築する
TICK は以下の Influxdb 改め influxdata ツール群で構成される stack らしい
- T - Telegraf – Data collection
- I - InfluxDB – Data storage
- C - Chronograf – Data visualization
- K - Kapacitor – Data processing
構成は以下の通り
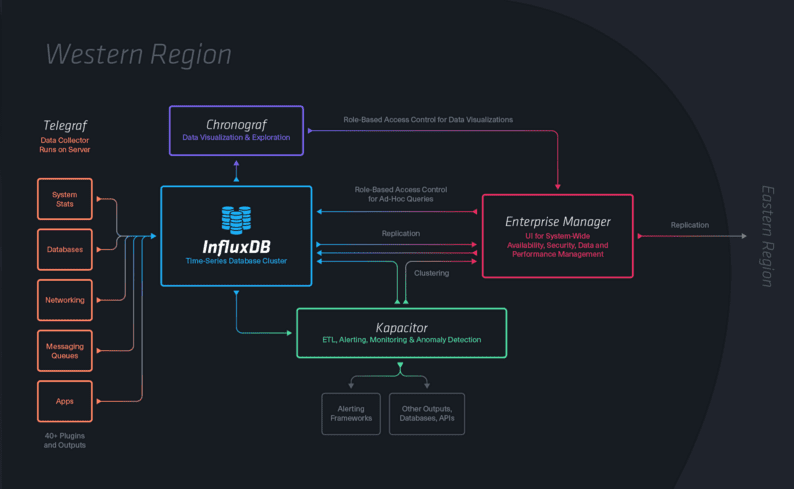
※公式サイトより
環境
AWS にサーバを2台用意
- ip-172-31-17-95 : Influxdb, Kapacitor, Chronograf
- ip-172-31-17-94 : Telegraf
バージョンは以下の通り
- CentOS release 6.7 (Final)
- InfluxDB v0.10.0 (Beta)
- Telegraf v0.10.0
- Kapacitor v0.2.4
- Chronograf v0.4
各種インストール
InfluxDB インストール
$ wget https://influxdb.s3.amazonaws.com/influxdb-0.10.0-0.beta1.x86_64.rpm
$ sudo yum localinstall influxdb-0.10.0-0.beta1.x86_64.rpm
Telegraf インストール
$ wget http://get.influxdb.org/telegraf/telegraf-0.10.0-1.x86_64.rpm
$ sudo yum localinstall telegraf-0.10.0-1.x86_64.rpm
Kapacitor インストール
$ wget https://s3.amazonaws.com/influxdb/kapacitor-0.2.4-1.x86_64.rpm
$ sudo yum localinstall kapacitor-0.2.4-1.x86_64.rpm
Chronograf インストール
$ wget https://s3.amazonaws.com/get.influxdb.org/chronograf/chronograf-0.4.0-1.x86_64.rpm
$ sudo yum localinstall chronograf-0.4.0-1.x86_64.rpm
InfluxDB セットアップ
とりあえずデフォルトのまま起動
$ sudo /etc/init.d/influxdb start
Telegraf セットアップ
- InfluxDB サーバを指定する
- per cpu は無効にする
/etc/telegraf/telegraf.conf
urls = ["http://172.31.17.95:8086"]
[[inputs.cpu]]
percpu = false
Telegraf起動
$ sudo /etc/init.d/telegraf start
デフォルトで入る監視設定は以下
| measurement | field |
|---|---|
| cpu | time_guest, time_guest_nice time_idle, time_iowait, time_irq, time_nice, time_softirq, time_steal, time_system, time_user, usage_guest, usage_guest_nice, usage_idle, usage_iowait, usage_irq, usage_nice, usage_softirq, usage_steal, usage_system, usage_user |
| disk | free, fstype, inodes_free, inodes_total, inodes_used, path, total, used |
| diskio | io_time name, read_bytes, read_time, reads, serial, write_bytes, write_time, writes |
| mem | available, available_percent, buffered, cached, free, total, used, used_percent |
| swap | free, in, out, total, used, used_percent |
| system | load1, load15, load5 |
※10秒毎に上記メトリクスを InfluxDB に output する
Kapacitor セットアップ
email 通知を有効化
/etc/kapacitor/kapacitor.conf
[smtp]
enabled = true #有効化
host = "127.0.0.1"
port = 25
username = ""
password = ""
from = "test@quickguard.net" #送信元アドレス
to = ["****@*************"] #アラートメール通知先
no-verify = false
idle-timeout = "30s"
Kapacitor 起動
$ sudo /etc/init.d/kapacitor start
アラート設定
tick スクリプトを作成
cpu_alert.tick
stream
.from().measurement('cpu')
.alert()
.warn(lambda: "usage_idle" < 30) #idle 30%以下で warning
.crit(lambda: "usage_idle" < 10) #idle 30%以下で critical
.email() #email 通知
task を投入
$ kapacitor define -name cpu_alert -type stream -dbrp telegraf.default -tick cpu_alert.tick
task の有効化
$ kapacitor enable cpu_alert
監視対象のスペックが低いこともあり、軽く負荷かけると大量にメールが飛んできた

メールの件名でホスト名部分が nil になっているので修正する
flapping もうざいので何とかする
アラート調整
- TagKey を group 化 (host, cpu)
- window の定義を追加 (60秒毎に60秒間のデータを取得)
- warn, crit 60秒間のデータの何れかが条件に一致した場合、alert に投げる
- stateChangesOnly 追加 (ステータスが変化したときのみ)
- ID 追加 (メールの件名に使用される message が {{ .ID }} is {{ .Level }} のため)
cpu_alert.tick
stream
.from().measurement('cpu')
.groupBy('host','cpu')
.window()
.period(60s)
.every(60s)
.alert()
.id('{{ index .Tags "host" }}/{{ index .Tags "cpu" }}')
.warn(lambda: "usage_idle" < 30)
.crit(lambda: "usage_idle" < 10)
.stateChangesOnly()
.email()
task 再投入
$ kapacitor define -name cpu_alert -type stream -dbrp telegraf.default -tick cpu_alert.tick
確認
$ kapacitor show cpu_alert
Name: cpu_alert
Error:
Type: stream
Enabled: true
Executing: true
Databases Retention Policies: ["telegraf"."default"]
TICKscript:
stream
.from().measurement('cpu')
.groupBy('host','cpu')
.window()
.period(60s)
.every(60s)
.alert()
.id('{{ index .Tags "host" }}/{{ index .Tags "cpu" }}')
.warn(lambda: "usage_idle" < 30)
.crit(lambda: "usage_idle" < 10)
.stateChangesOnly()
.email()
DOT:
digraph cpu_alert {
stream0 -> stream1 [label="12"];
stream1 -> window2 [label="1"];
window2 -> alert3 [label="0"];
}
task 一覧取得
$ kapacitor list tasks
Name Type Enabled Executing Databases and Retention Policies
cpu_alert stream true true ["telegraf"."default"]
アラートメール確認

注意事項
tick スクリプトの構文エラーは define 時にチェックされてエラーになる、ランタイムエラーが出るような task を突っ込むと panic になって落ちた後、起動不可になった
こんなの(groupBy を下に持ってくる)
cpu_alert.tick
stream
.from().measurement('cpu')
.window()
.period(30s)
.every(30s)
.groupBy('host','cpu')
.alert()
.warn(lambda: "usage_idle" < 30)
.crit(lambda: "usage_idle" < 10)
.log('/tmp/cpu_alert.log'
対応 : task db を削除して初期化した
$ sudo rm /var/lib/kapacitor/tasks/task.db
Chronograf セットアップ
外からアクセスできるようにする
/opt/chronograf/config.toml
Bind = "0.0.0.0:10000"
Chronograf 起動
$ sudo /etc/init.d/chronograf start
http://{サーバIPアドレス}:10000 にアクセス

「Add new server」より「NICKNAME」を適当に入力して「Save」 ↓ 「New Graph」にてグラフ名を設定して「BUILDER」でクエリ作成
telegraf で取得した cpu メトリクスのグラフ
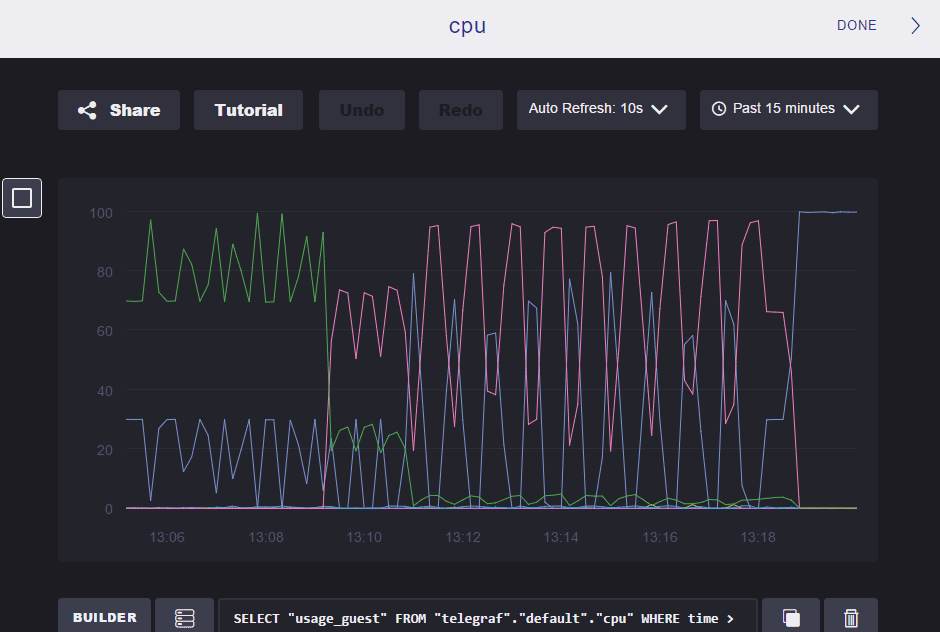
次回は telegraf によるメトリクス取得と kapacitor でのイベント処理について深堀する