Telegraf と Kapacitor で値を集約してから InfluxDB に送る

はじめに
平素は大変お世話になっております。
クイックガードのパー子です。
弊社では一部の監視システムに InfluxData の TICKスタック を使っています。
監視対象によってはメトリクス数が非常に多く、増大しがちな InfluxDB (= データ・ストア) の負担を抑えたいという課題がありました。
(真っ先に限界を迎えるのはいつだってバックエンドなので。)
データ・ストアのオフロードのため、メトリクス・コレクタである Telegraf の側で値を取捨、加工し、少数の統計値に集約してから InfluxDB に送出する仕組みを検討したのでご紹介します。
対象メトリクス
この記事では題材として Fastly のメトリクス を扱います。
そのうち、特にクラスごとのステータス・コード (= status_1xx 〜 status_5xx) に着目していきます。
このメトリクスを Prometheus input plugin + peterbourgon/fastly-exporter 経由で取得すると、以下のようにデータセンターごとのデータ・シリーズが fastly_rt_status_group_total というフィールド名で生成されます。
$ telegraf --config /etc/telegraf/telegraf.conf --test | grep 'fastly_rt_status_group_total='
2021-03-11T02:49:53Z I! Starting Telegraf 1.17.2
...
> fastly,datacenter=VIE,service_id=xxxxxx,service_name=example.com,status_group=4xx fastly_rt_status_group_total=0 1614762291000000000
> fastly,datacenter=VIE,service_id=xxxxxx,service_name=example.com,status_group=5xx fastly_rt_status_group_total=0 1614762291000000000
> fastly,datacenter=WDC,service_id=xxxxxx,service_name=example.com,status_group=1xx fastly_rt_status_group_total=0 1614762291000000000
> fastly,datacenter=WDC,service_id=xxxxxx,service_name=example.com,status_group=2xx fastly_rt_status_group_total=1 1614762291000000000
> fastly,datacenter=WDC,service_id=xxxxxx,service_name=example.com,status_group=3xx fastly_rt_status_group_total=0 1614762291000000000
> fastly,datacenter=WDC,service_id=xxxxxx,service_name=example.com,status_group=4xx fastly_rt_status_group_total=0 1614762291000000000
> fastly,datacenter=WDC,service_id=xxxxxx,service_name=example.com,status_group=5xx fastly_rt_status_group_total=0 1614762291000000000
> fastly,datacenter=WLG,service_id=xxxxxx,service_name=example.com,status_group=1xx fastly_rt_status_group_total=0 1614762291000000000
> fastly,datacenter=WLG,service_id=xxxxxx,service_name=example.com,status_group=2xx fastly_rt_status_group_total=1 1614762291000000000
> fastly,datacenter=WLG,service_id=xxxxxx,service_name=example.com,status_group=3xx fastly_rt_status_group_total=0 1614762291000000000
> fastly,datacenter=WLG,service_id=xxxxxx,service_name=example.com,status_group=4xx fastly_rt_status_group_total=0 1614762291000000000
> fastly,datacenter=WLG,service_id=xxxxxx,service_name=example.com,status_group=5xx fastly_rt_status_group_total=0 1614762291000000000
> fastly,datacenter=YUL,service_id=xxxxxx,service_name=example.com,status_group=1xx fastly_rt_status_group_total=0 1614762291000000000
> fastly,datacenter=YUL,service_id=xxxxxx,service_name=example.com,status_group=2xx fastly_rt_status_group_total=0 1614762291000000000
...
これらのメトリクスをクラスごとに集約し、全データセンターの値を合計した結果だけを InfluxDB に保存してみます。
ちなみにデータセンターを数えてみたところ、現時点で 79個ありました。
$ curl -s -H 'Fastly-Key: {{ APIトークン }}' https://api.fastly.com/datacenters \
| jq -r '.[].code'
AMS
IAD
WDC
BWI
DCA
FTY
...
Telegraf単独では難しい
Telegraf はプラグイン機構を備えており、その中に Aggregator plugins というものがあります。
いかにもそれっぽい名前なのですが、残念ながら今回の用途には使えません。
というのも、このタイプのプラグインは、単一のデータ・シリーズやフィールドをスコープとして一定の時間ウィンドウで (例えば 30秒区切りで) 値を集約するためのものなのです。
今回のように、異なるデータセンター (= 異なるデータ・シリーズ) にまたがった集約はできません。
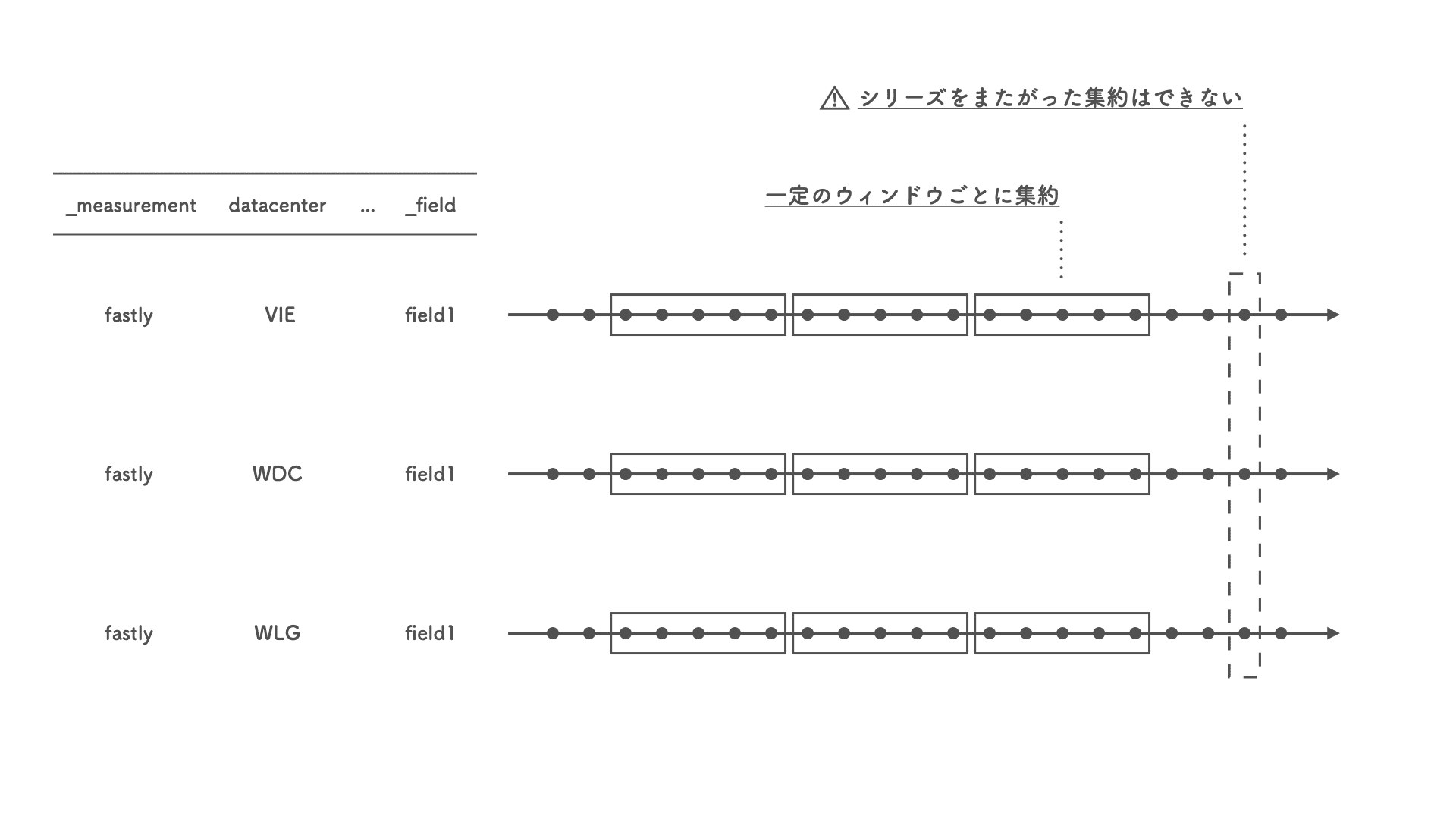
Kapacitor を使う
今回の用途には、TICKスタックの 1つ Kapacitor が適していそうです。
Telegraf と InfluxDB の間に Kapacitor を挟んで、Kapacitor で値を集約したうえで InfluxDB に格納します。

Kapacitor の繋ぎ方
InfluxDB は v1 と v2 でインタフェイスが大きく異なります。
v2 は GA版がリリースされてから日が浅く、まだこなれていませんが、今回は敢えて v2 でいってみます。
基本的に 公式ドキュメント にしたがって設定しますが、いくつか罠があるので注意が必要です。
Telegraf » Kapacitor
ここの繋ぎ方は簡単で、InfluxDB v1.x output plugin がそのまま使えます。
/etc/telegraf/telegraf.conf
[[outputs.influxdb]]
urls = ["http://localhost:9092"]
database = "telegraf"
retention_policy = "autogen"
urls には Kapacitor のアドレスを指定します。
database と retention_policy は任意の値で OK です。
Kapacitor はこの DBRP (Database + Retention policy) からメトリクスを読み込みます。
なお、Telegraf を実行するとデータベースの作成に失敗した旨の警告が出ますが、無視して構わないようです。
$ telegraf --config /etc/telegraf/telegraf.conf --once
2021-03-10T07:31:30Z I! Starting Telegraf 1.17.2
2021-03-10T07:31:30Z W! [outputs.influxdb] When writing to [http://localhost:9092]: database "telegraf" creation failed: 404 Not Found
2021-03-10T07:31:30Z I! [agent] Hang on, flushing any cached metrics before shutdown
Kapacitor » InfluxDB
Kapacitor は v1互換API で InfluxDB とやり取りします。
先述の公式ドキュメントの記載どおりではうまくいかないので、フォーラム を参考に設定していきます。
まず、v1用クレデンシャルを発行します。
$ influx v1 auth create \
--org '{{ Organization }}' \
--username '{{ ユーザ名 }}' \
--read-bucket '{{ バケットID }}' \
--write-bucket '{{ バケットID }}'
バケットID は $ influx bucket list で確認できます。
$ influx bucket list
ID Name Retention Organization ID
c8c5460b957ab2bc _monitoring 168h0m0s f311cbc29d0f057e
64b7587698210916 _tasks 72h0m0s f311cbc29d0f057e
aaaa558a039818e6 my-bucket 0s f311cbc29d0f057e
今回はバケット my-bucket に対して読み書き権限のあるユーザ kapacitor を作成してみました。
$ influx v1 auth list
ID Description Name / Token User Name User ID Permissions
072affc1ce40a000 for kapacitor kapacitor gondawara_yumeko 0717c3318aedb000 [read:orgs/f311cbc29d0f057e/buckets/aaaa558a039818e6 write:orgs/f311cbc29d0f057e/buckets/aaaa558a039818e6]
この v1クレデンシャルのユーザ名とパスワードを kapacitor.conf に記述します。
また、InfluxDB v2 は Subscription API を持たないので無効化します。
/etc/kapacitor/kapacitor.conf
[[influxdb]]
urls = ["http://localhost:8086"]
username = "{{ ユーザ名 }}"
password = "{{ パスワード }}"
disable-subscriptions = true
続いて、Kapacitor の書き込み先の DBRP とバケットをマッピングします。
$ influx v1 dbrp create \
--db '{{ DB }}' \
--rp '{{ Retention policy }}' \
--bucket-id '{{ バケットID }}}'
以下は DBRP kapacitor.autogen とバケット my-bucket (ID: aaaa558a039818e6) をマッピングしてみたところです。
$ influx v1 dbrp list
ID Database Bucket ID Retention Policy Default Organization ID
072b00e95e40a000 kapacitor aaaa558a039818e6 autogen true f311cbc29d0f057e
集約する
TICKスクリプト で集約処理を定義します。
これを ETLジョブとして Kapacitor に登録しておくことで、Telegraf から流れてくるメトリクスがストリーミングで処理されるようになります。
ここまで設定したとおり、Telegraf から届くメトリクスを DBRP telegraf.autogen から読み込み、集約して、その結果を InfluxDB の DBRP kapacitor.autogen に書き込むように TICKスクリプトを記述します。
次の例では クラスごとのステータス・コード を全データセンターにわたって集約し、合計と平均を算出してみます。
スクリプト
fastly_status_group.tick というファイル名で作成します。
fastly_status_group.tick
dbrp "telegraf"."autogen" // 1
var fastly_rt_status_group_total = stream // 2
|from() // .
.measurement('fastly') // .
.where(lambda: isPresent("fastly_rt_status_group_total")) // .
fastly_rt_status_group_total // 3
|groupBy('service_id', 'status_group') // .
|sum('fastly_rt_status_group_total') // 4
.as('status_group_total_sum') // 5
|influxDBOut() // 6
.database('kapacitor') // .
.retentionPolicy('autogen') // .
.measurement('fastly') // .
fastly_rt_status_group_total // 7
|groupBy('service_id', 'status_group') // .
|mean('fastly_rt_status_group_total') // .
.as('status_group_total_mean') // .
|influxDBOut() // .
.database('kapacitor') // .
.retentionPolicy('autogen') // .
.measurement('fastly') // .
- まず最初に Telegraf からのインプット (DBRP:
telegraf.autogen) を処理対象とすることを宣言する。 - 続いて、対象のメトリクスのみピックアップし、いったん変数
fastly_rt_status_group_totalに格納する。 - それを
groupBy()で FastlyサービスID とステータス・コードごとにグルーピングする。 - さらに
sum()することで全データセンターの値を合計する。 - 合計値のフィールド名は
status_group_total_sumとした。 - 最後に
influxDBOut()で DBRPkapacitor.autogenの Measurementfastlyへ書き込む。 - 同様に平均値も集約する。
ジョブ登録
作成した TICKスクリプトは ETLジョブとして Kapacitor に登録&有効化することで実行されるようになります。
$ kapacitor define {{ ジョブ名 }} -tick {{ TICKスクリプト }}
$ kapacitor enable {{ ジョブ名 }}
先ほど例示したスクリプトをジョブ fastly_status_group として登録しました。
$ kapacitor define fastly_status_group -tick fastly_status_group.tick
$ kapacitor enable fastly_status_group
結果
値が正しく集約されているか、InfluxDB の Web UI で確認してみましょう。
まず、集約前の Rawメトリクスを見てみます。
(比較のためにあらかじめ raw.autogen に Rawメトリクスを格納しておきました。)

データセンターごとのデータ・シリーズが何本も描画されています。
ゴチャゴチャしていますね。
続いて Kapacitor で集約したメトリクスです。
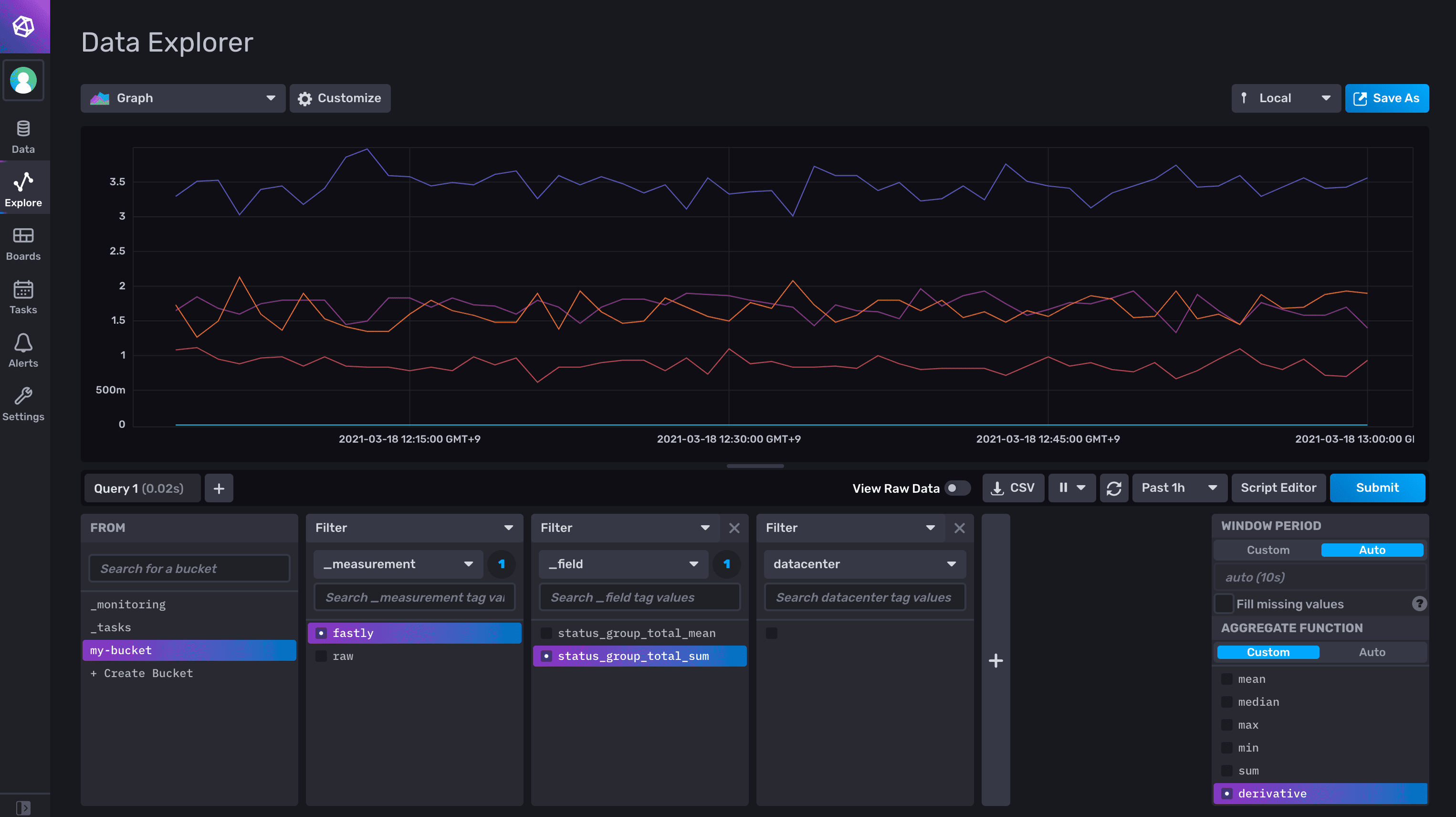
狙いどおり、きっかり 5本 (1xx 〜 5xx) に畳まれています。
(ちょっとわかりづらいですが、1xx の値は終始 0 でした。)
まとめ
InfluxDataプラットフォームにおいて、データ・シリーズにまたがった値の集約処理をメトリクス・コレクタ側で実行する方法を検討しました。
この処理は Telegraf単独では難しく、TICKスタックの一角である Kapacitor を採用することで期待する集約を実現できました。
今回の記事で試したのは単純な集約処理だけでしたが、応用の幅は広そうです。
InfluxDB v2 との繋ぎ込みには少々工夫が要るため、そのあたりのわかりづらさは今後の改善に期待したいところです。
今後ともよろしくお願い申し上げます。