AWS Step Functions でジョブ管理システムを組む

はじめに
平素は大変お世話になっております。
クイックガードのパー子です。
ちょっとしたジョブを定期的なスケジュールで実行するには cron が便利でお手軽なのですが、それなりの規模になってくるとジョブ同士のオーケストレーションや安定した運用のために専用のジョブ管理システムが必須になってきます。
ところが従来型の製品としてのジョブ管理システムの運用はなかなか難しく、できれば避けたいというのが本音であります。
そこで本記事では、運用負荷を抑えるために、AWS Step Functions を主軸にマネージド・サービスを組み合わせたジョブ管理システムを組んでみたのでご紹介します。
この記事が対象とするシステム
「昔ながらの VM の上で動く、温かみのある cron を代替する」というシナリオを想定しています。
現代的なコンテナ・プラットフォームにはプラットフォーム自体にある程度の管理機能が組み込まれており、加えて Argo Workflows などの良質なワークフロー・エンジンが存在するため、それらの環境は本記事の対象外です。
ジョブ管理システムとは
バッチ処理プログラムなどのジョブを決められたタイミングで起動し、終了ステータスを監視してリトライやアラートを飛ばすなどのエラー制御をしたり、複数のジョブを連続的/並列的に実行したりするシステムのことです。
多数のジョブが存在する環境では必須のシステムと言えます。
ジョブ管理システムには主に以下の機能が求められます。
| 機能 | 説明 |
|---|---|
| フロー制御 | ジョブ同士の前後/並列関係を定義したり、エラー時にリトライしたりする。 |
| トリガー | 指定した日時にジョブを起動するほか、ファイルの状態変化を起動契機にしたり、即時に手動実行するインタフェイスを提供する。 |
| リソース・スケジューリング | どのワーカ・ノードにジョブを割り当てるか決定する。例えば、リソースに空きがあるノードや、そのジョブを実行するに足るスペックのノードなど、一定のルールに基づいて自動的に判断する。 |
| アラーティング | ジョブが異常終了したり、起動/終了予定日時を超過した場合にアラートを飛ばす。 |
| モニタリング | ジョブの終了ステータス、実行時間、消費したワーカ・ノードのリソース、ログなどを保存、表示する。 |
代表的な製品は、OSS なら Rundeck や Hinemos、商用なら JP1 (日立)、WebSAM (NEC)、Systemwalker (富士通) などでしょうか。
ジョブ管理システムは文字どおりジョブ実行の根幹を担っているため、全システムの構成要素の中でも極めて高い可用性が求められます。
これを自前で運用するのは非常に面倒なのでフルマネージドな AWS のサービスに丸投げしたい、というのが今回の記事の動機です。
コンセプト

一連のジョブのフロー (ジョブ・ネットワーク) を Step Functions で制御し、Systems Manager の Run Command を使ってインスタンス内でコマンドを実行、EventBridge でフローを起動する、というのが基本のコンセプトです。
以下、前セクションで述べたジョブ管理システムの主要機能について、今回の仕組みでどう実現するか解説します。
フロー制御
Step Functions でジョブの前後関係とエラー時のリトライを制御します。
ただし、再試行すれば成功する可能性のあるエラーのみリトライすべきなので、ジョブ・プログラムのほうでエラーの種類を判別し、Step Functions に提示する一手間が必要です。
State machine のタイプ には Standard と Express があり、実行時間の上限や Execution semantics (= Exactly once とか At least once とか) が異なります。
長時間実行されること&Exactly once で起動したいことから、Standardタイプを選択します。
トリガー
EventBridge でトリガーします。
cron式で日時指定できるほか、AWSサービスの各種イベントを契機とすることもできるので、非常に柔軟です。
リソース・スケジューリング
Systems Manager の Automation と Run Command を組み合わせます。
Automation の aws:executeScriptアクション でワーカ・ノードを選択し、そのノードに対して Run Command でコマンドを送り込みます。
aws:executeScriptアクションでは Python または PowerShell の任意のスクリプトを実行できるので、自由にノード選択ロジックを定義できます。
アラーティング
ジョブの実行に失敗した場合、これをトラップして EventBridge にイベントを飛ばします。
ステートの変化ごとに自動で発行されるイベント には State machine の実行結果の詳細が含まれず、きめ細かい対処ができないため、State machine内の 1ステップで明示的に EventBridge の API を叩いてイベントを発行するようにします。
なお、起動/終了予定日時を超過した際のアラートは、超過の検知が難しいため、今回の記事では未実装です。
モニタリング
ジョブの実行状況は Step Functions や Systems Manager のコンソールで、ワーカ・ノードのリソース状況は CloudWatch でチェックします。
ログは S3 や CloudWatch Logs に格納します。
Run Command のレイヤー でロギングするのが素直でしょう。
この際、コマンドを実行するインスタンス の IAMロールに相応の書き込み権限を付与しておく必要があります。
コマンドの出力は Run Command のコンソール上でも確認できるのですが、文字数の制限があり、超過した分は捨てられてしまいます。
ドキュメントには 上限 2,500 文字 と書かれていますが、
By default, Systems Manager returns only the first 2,500 characters of the command output.
コンソールだと 48,000文字となっていました。

いずれにしてもコンソールでは心許ないので S3 や CloudWach Logs に格納しておきたいですね。
また、Step Functions は X-Ray をサポートしている ので、必要であれば活用できます。
ジョブ管理システムとしては各ジョブ・ネットワークの実行結果の一覧画面 (= 縦にジョブ・ネットワークを並べ、横に時間軸を伸ばし、実行時間と実行ステータスをマッピングしたもの) も欲しいところですが、Step Functions にはそのようなジョブ管理システム特化の機能はないので残念ながら自作しないといけません。
仕組み詳細
今回の仕組みの中核であるコマンド実行部分とアラート部分は、汎用的な部品として独立した State machine にしておくと使い勝手が良いです。
コマンド実行
メインの機能であるワーカ・ノードの選択 〜 コマンド実行処理を System Manager Automation で実装し、親ジョブ・ネットワークから呼び出しやすいように Step Functions でラップします。
以降はこの State machine を RunJob という名前で呼びます。
呼び出し方式

まず、親ジョブ・ネットワークは State machine RunJob の実行完了を待ち合わせるため、wait-token方式 (= Wait for a Callback with the Task Token) で呼び出します。
ちなみに他の方式だと、default方式 (= Request Response) は子State machine の完了を待ち合わせずに次のステップに進んでしまうのでダメです。
sync方式 (= Run a Job) は完了を待ち合わせてくれるのですが、子State machine の実行失敗時のエラー・レスポンスをカスタマイズできないので親側でのエラー・ハンドリングが困難です。
一方、wait-token方式なら エラー・レスポンスをカスタマイズ できるのです。
(コールバックする分だけ sync方式よりも手間がかかりますが。)
同様に、Automation も実行完了を待ち合わせるために wait-token方式で呼び出します。
なお、Automation は Step Functions の Optimized integrations に含まれないので、sync方式は使えません。
(Optimized integrations ではなく AWS SDK service integrations で連携します。)
Automation
Automation には、ワーカ・ノードの選択とそのノード上でのコマンド実行を担わせます。

- 実行対象のインスタンスを Pythonスクリプト で 1台選択
- System Manager Run Command で当該ノード上にてコマンド実行
- コマンドの成否を Step Functions に コールバック
Automationドキュメント名は RunShellScriptOnOneInstance としました。
Automationドキュメント: RunShellScriptOnOneInstance
description: 指定したタグを持つインスタンス群のうち、1台でコマンドを実行する。
schemaVersion: '0.3'
assumeRole: 'arn:aws:iam::********:role/********'
outputs:
- runCommand.OutputPayload
parameters:
Tags:
description: |-
タグ
(形式: {"<TAG_NAME>": "<VALUE>", ...})
type: StringMap
Commands:
description: コマンド
type: StringList
displayType: textarea
WorkingDirectory:
description: ワーキング・ディレクトリ
type: String
default: ''
ExecutionTimeout:
description: タイムアウト (秒)
type: String
default: '3600'
TaskToken:
description: |-
Step Functions タスク・トークン
https://docs.aws.amazon.com/step-functions/latest/dg/connect-to-resource.html#connect-wait-token
type: String
mainSteps:
- name: getInstanceId
description: 実行対象のインスタンスを 1台選択する。
action: 'aws:executeScript'
inputs:
Runtime: python3.7
Handler: script_handler
Script: |-
import random
import boto3
def script_handler(events, context):
ids = instance_ids(
describe_instances(events['tags'])
)
print(ids)
return select_instance(ids)
def instance_ids(payload):
return [
instances['InstanceId'] for launch_request in payload['Reservations'] for instances in launch_request['Instances']
]
def describe_instances(tags):
return boto3.client('ec2').describe_instances(
Filters=(
cond_tags(tags) + cond_instance_status()
)
)
def cond_tags(tags):
return [
{
'Name': f'tag:{ k }',
'Values': [
v
]
} for k, v in tags.items()
]
def cond_instance_status():
return [
{
'Name': 'instance-state-name',
'Values': [
'running'
]
}
]
def select_instance(ids):
return random.choice(ids)
InputPayload:
tags: '{{ Tags }}'
outputs:
- Name: instanceId
Selector: $.Payload
Type: String
onFailure: 'step:callbackWorkerBusy'
onCancel: 'step:callbackFailure'
- name: runCommand
description: 選択した 1台でコマンドを実行する。
action: 'aws:runCommand'
inputs:
DocumentName: AWS-RunShellScript
InstanceIds:
- '{{ getInstanceId.instanceId }}'
Parameters:
commands: '{{ Commands }}'
workingDirectory: '{{ WorkingDirectory }}'
executionTimeout: '{{ ExecutionTimeout }}'
CloudWatchOutputConfig:
CloudWatchOutputEnabled: true
OutputS3BucketName: quickguard-example
OutputS3KeyPrefix: run_command/logs
TimeoutSeconds: 600
onFailure: Continue
isCritical: true
- name: chooseTaskResult
description: Step Functions にコールバックする結果を選択する。
action: 'aws:branch'
inputs:
Choices:
- NextStep: callbackSuccess
Variable: '{{ runCommand.Status }}'
StringEquals: Success
Default: callbackFailure
- name: callbackSuccess
description: Step Functions にタスクが成功した旨をコールバックする。
action: 'aws:executeAwsApi'
inputs:
Service: stepfunctions
Api: SendTaskSuccess
output: |-
{
"AutomationExecutionURL": "https://ap-northeast-1.console.aws.amazon.com/systems-manager/automation/execution/{{ automation:EXECUTION_ID }}?region=ap-northeast-1",
"CommandResult": {{ runCommand.OutputPayload }}
}
taskToken: '{{ TaskToken }}'
isEnd: true
- name: callbackFailure
description: Step Functions にタスクが失敗した旨をコールバックする。
action: 'aws:executeAwsApi'
inputs:
Service: stepfunctions
Api: SendTaskFailure
cause: |-
{
"AutomationExecutionURL": "https://ap-northeast-1.console.aws.amazon.com/systems-manager/automation/execution/{{ automation:EXECUTION_ID }}?region=ap-northeast-1",
"CommandResult": {{ runCommand.OutputPayload }}
}
error: ExecutionFailed
taskToken: '{{ TaskToken }}'
isEnd: true
- name: callbackWorkerBusy
description: Step Functions にワーカが Busy である旨をコールバックする。
action: 'aws:executeAwsApi'
inputs:
Service: stepfunctions
Api: SendTaskFailure
cause: |-
{
"AutomationExecutionURL": "https://ap-northeast-1.console.aws.amazon.com/systems-manager/automation/execution/{{ automation:EXECUTION_ID }}?region=ap-northeast-1"
}
error: WorkerBusy
taskToken: '{{ TaskToken }}'
isEnd: true
今回の実装ではタグでインスタンスを絞り込み、さらにその中からランダムで 1台選択しています。
都合に合わせて任意の選択ロジックに書き換えるとよいでしょう。
(例えば、インスタンスの負荷や、ジョブとの親和性など。)
コマンドの 終了ステータスが 0 ならコマンド成功として SendTaskSuccess を、それ以外ならコマンド失敗として SendTaskFailure を Step Functions にコールバックします。
インスタンス選択の段階で失敗した場合は、後述するように何度かリトライするため、errorパラメータに WorkerBusy を指定したうえで SendTaskFailure を投げます。
他にも呼び出し元の Step Functions側で細かく対処したい場合は、errorパラメータでエラーの種類を伝えるとよいでしょう。
IAMロールには、Automation実行のための基本的な権限の他に、インスタンスID を取得するための ec2:DescribeInstances と Step Functions にコールバックするための states:SendTask* が必要です。
Step Functions
やっていることは前述の Automation の実行だけで、あとはその結果を親ジョブ・ネットワークにコールバックしています。

State machine名は RunJob です。
State machine: RunJob
{
"StartAt": "Run job",
"States": {
"Run job": {
"Type": "Task",
"Resource": "arn:aws:states:::aws-sdk:ssm:startAutomationExecution.waitForTaskToken",
"Parameters": {
"DocumentName": "RunShellScriptOnOneInstance",
"Parameters": {
"TaskToken.$": "States.Array($$.Task.Token)",
"Tags.$": "States.Array($.Tags)",
"Commands.$": "$.Commands",
"WorkingDirectory.$": "States.Array($.WorkingDirectory)",
"ExecutionTimeout.$": "States.Array($.ExecutionTimeout)"
}
},
"Next": "Callback success",
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"Next": "Callback failure"
}
],
"Retry": [
{
"ErrorEquals": [
"WorkerBusy"
],
"BackoffRate": 2,
"IntervalSeconds": 100,
"MaxAttempts": 2
}
]
},
"Callback success": {
"Type": "Task",
"Resource": "arn:aws:states:::aws-sdk:sfn:sendTaskSuccess",
"Parameters": {
"Output.$": "$",
"TaskToken.$": "$$.Execution.Input.TaskToken"
},
"Retry": [
{
"ErrorEquals": [
"States.ALL"
],
"BackoffRate": 1,
"IntervalSeconds": 5,
"MaxAttempts": 2
}
],
"Next": "Success"
},
"Success": {
"Type": "Succeed"
},
"Callback failure": {
"Type": "Task",
"Resource": "arn:aws:states:::aws-sdk:sfn:sendTaskFailure",
"Parameters": {
"Error.$": "$.Error",
"Cause.$": "$.Cause",
"TaskToken.$": "$$.Execution.Input.TaskToken"
},
"Retry": [
{
"ErrorEquals": [
"States.ALL"
],
"BackoffRate": 1,
"IntervalSeconds": 5,
"MaxAttempts": 2
}
],
"Next": "Fail"
},
"Fail": {
"Type": "Fail"
}
}
}
親ジョブ・ネットワークから呼び出す際に、ワーカ・ノードのタグや実行するコマンド、ワーキング・ディレクトリなどのほか、コールバックする際に付与する Task token を引数として与えます。
Automation を呼び出す際のパラメータは、型がなんであれ Array でないといけない ので、組み込み関数 States.Array() で Array に包みます。
Automation の実行結果に応じて SendTaskSuccess または SendTaskFailure を Step Functions にコールバックし、続いてそれぞれのステータス (= Success または Fail) で State machine を決着させます。
Automation が WorkerBusyエラーを返した (= ワーカ・ノードの選択に失敗した) 場合は何度かリトライし、ノードが利用可能になるのを待ちます。
Automation に渡す Task token は RunJob自身の Context のものを渡すので $$.Task.Token を、親ジョブ・ネットワークにコールバックする際は親から引数として渡されたものを指定します。
(State machine に渡された引数は Context object の $$.Execution.Input に格納されています。)
IAMロールとして、Automation を操作するための ssm:*Automation* と Step Functions にコールバックするための states:SendTask* が必要です。
アラート
コマンドが失敗した場合、然るべき通知先にアラートを飛ばして異常を知らせる必要があります。
前述 のように、FAILEDステートを一括でハンドリングする方法では細かい制御が難しいため、State machine内で EventBridge API を叩き、カスタマイズしたペイロードを送出するようにしています。

State machine名は SendFailEvent です。
State machine: SendFailEvent
{
"StartAt": "Send",
"States": {
"Send": {
"Type": "Task",
"Resource": "arn:aws:states:::events:putEvents",
"Parameters": {
"Entries": [
{
"Source": "net.quickguard.states",
"DetailType": "Job Network Execution Fail",
"Detail": {
"executionURL.$": "States.Format('https://ap-northeast-1.console.aws.amazon.com/states/home?region=ap-northeast-1#/executions/details/{}', $$.Execution.Input.AWS_STEP_FUNCTIONS_STARTED_BY_EXECUTION_ID)",
"error.$": "$.Error",
"cause.$": "States.StringToJson($.Cause)",
"channel.$": "$.Channel"
}
}
]
},
"End": true,
"Retry": [
{
"ErrorEquals": [
"States.ALL"
],
"BackoffRate": 1,
"IntervalSeconds": 5,
"MaxAttempts": 2
}
]
}
}
}
重要度や緊急度はジョブごとに異なるため、一般的に複数の通知チャネルが用意されます。
パラメータ Channel で任意のチャネル名を渡し、それを以下のように EventBridge側で参照してチャネルに応じた通知先へアラートを飛ばします。
Event pattern
{
"source": [
"net.quickguard.states"
],
"detail-type": [
"Job Network Execution Fail"
],
"detail": {
"channel": [
"{{ チャネル }}"
]
}
}
なお、AWS_STEP_FUNCTIONS_STARTED_BY_EXECUTION_ID は親State machine の Execution ID で、本来は親子の State machine を 関連付ける ために使いますが、ここではアラート時にジョブ・ネットワークの本体を指し示すためにイベントのペイロードに含めています。
IAMロールには events:PutEvents が必要です。
ジョブ・ネットワーク例
RunJob と SendFailEvent の 2つの State machine を使って実際にジョブ・ネットワークを作成し、実行してみます。
State machine
ジョブを 3つ連続して実行し、いずれかの実行に失敗した場合は即座に停止してアラートを飛ばす、という単純なものです。
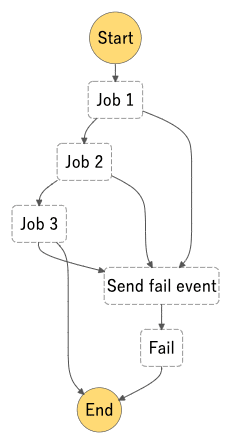
State machine名は JobNetwork-example としました。
State machine: JobNetwork-example
{
"StartAt": "Job 1",
"States": {
"Job 1": {
"Type": "Task",
"Resource": "arn:aws:states:::states:startExecution.waitForTaskToken",
"Parameters": {
"StateMachineArn": "arn:aws:states:ap-northeast-1:********:stateMachine:RunJob",
"Input": {
"AWS_STEP_FUNCTIONS_STARTED_BY_EXECUTION_ID.$": "$$.Execution.Id",
"TaskToken.$": "$$.Task.Token",
"Tags.$": "$$.Execution.Input",
"Commands": [
"echo 'SUCCESS'",
"true"
],
"WorkingDirectory": "/tmp",
"ExecutionTimeout": "300"
}
},
"Next": "Job 2",
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"Next": "Send fail event"
}
]
},
"Job 2": {
"Type": "Task",
"Resource": "arn:aws:states:::states:startExecution.waitForTaskToken",
"Parameters": {
"StateMachineArn": "arn:aws:states:ap-northeast-1:********:stateMachine:RunJob",
"Input": {
"AWS_STEP_FUNCTIONS_STARTED_BY_EXECUTION_ID.$": "$$.Execution.Id",
"TaskToken.$": "$$.Task.Token",
"Tags.$": "$$.Execution.Input",
"Commands": [
"echo 'FAILURE'",
"false"
],
"WorkingDirectory": "/tmp",
"ExecutionTimeout": "300"
}
},
"Next": "Job 3",
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"Next": "Send fail event"
}
]
},
"Job 3": {
"Type": "Task",
"Resource": "arn:aws:states:::states:startExecution.waitForTaskToken",
"Parameters": {
"StateMachineArn": "arn:aws:states:ap-northeast-1:********:stateMachine:RunJob",
"Input": {
"AWS_STEP_FUNCTIONS_STARTED_BY_EXECUTION_ID.$": "$$.Execution.Id",
"TaskToken.$": "$$.Task.Token",
"Tags.$": "$$.Execution.Input",
"Commands": [
"echo 'NEVER EXECUTED'",
"true"
],
"WorkingDirectory": "/tmp",
"ExecutionTimeout": "300"
}
},
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"Next": "Send fail event"
}
],
"End": true
},
"Send fail event": {
"Type": "Task",
"Resource": "arn:aws:states:::states:startExecution.sync:2",
"Parameters": {
"StateMachineArn": "arn:aws:states:ap-northeast-1:********:stateMachine:SendFailEvent",
"Input": {
"AWS_STEP_FUNCTIONS_STARTED_BY_EXECUTION_ID.$": "$$.Execution.Id",
"Error.$": "$.Error",
"Cause.$": "$.Cause",
"Channel": "high"
}
},
"Next": "Fail"
},
"Fail": {
"Type": "Fail"
}
}
}
Job 2 は必ずエラーとなるようにしているため、Job 3 は実行されず、Start » Job 1 » Job 2 » Send fail event » Fail » End と遷移します。
RunJob は wait-token方式で呼び出したいので Task token と、加えて親子の関連付けのための AWS_STEP_FUNCTIONS_STARTED_BY_EXECUTION_ID を引数として与えます。
SendFailEvent はエラー・レスポンスの形式にこだわらないので sync方式で充分です。
なお、sync方式で State machine を呼び出す場合、この IAM権限 を与えておかないと極めて不親切なエラーを吐いて変更を阻まれるので注意です。
(内部的に EventBridge の StepFunctionsGetEventsForStepFunctionsExecutionRule というマネージドな Rule で子State machine の状態を監視しているようで、そのための権限を与えておかないといけないということだと思われます。)

ジョブ・ネットワークの定義と稼働環境を分離する (= ワーカ・ノードを簡単に切り替えられるようにする) ため、実行時の引数としてインスタンスのタグを指定するようにします。
実行時の引数
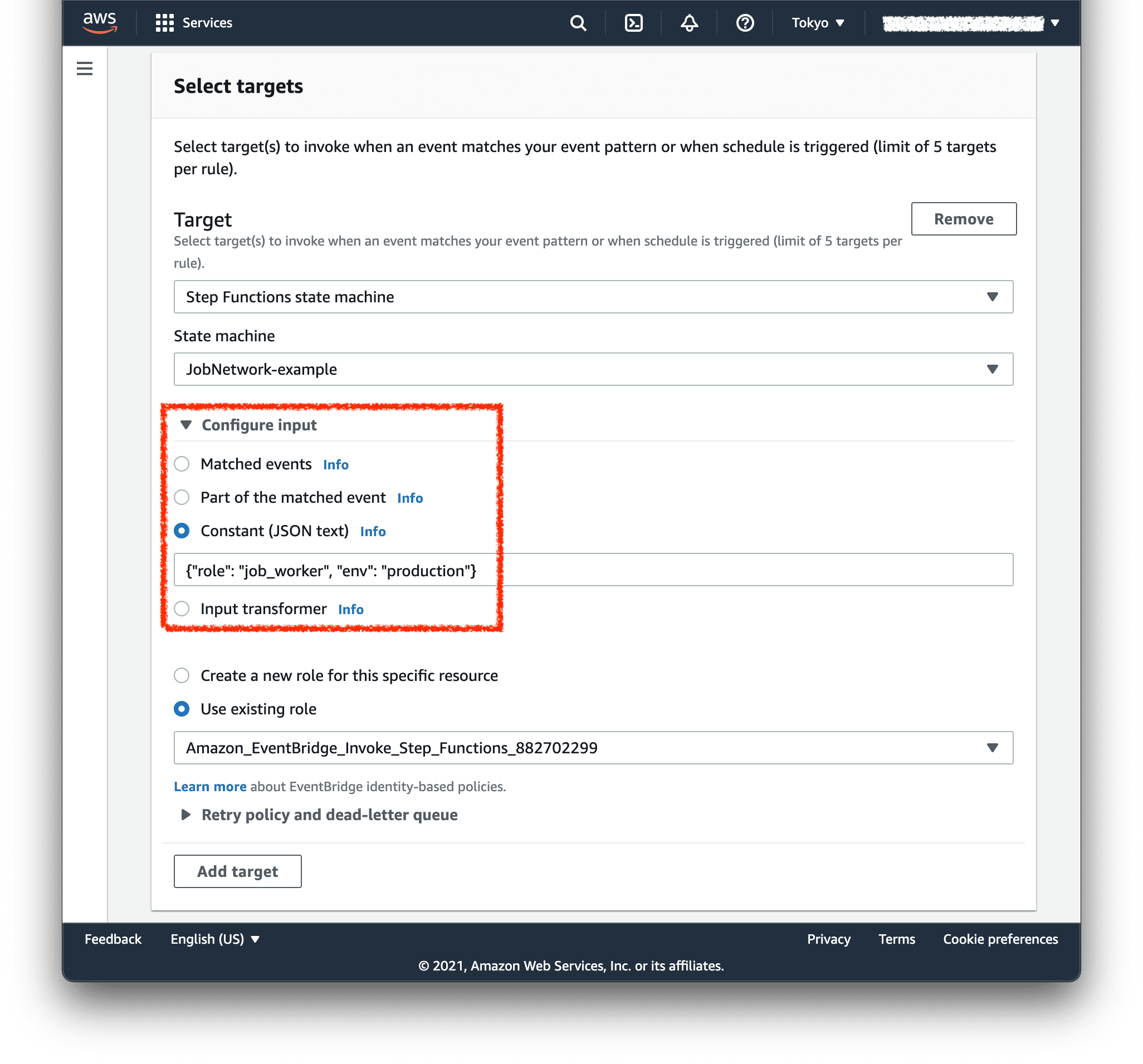
{
"role": "job_worker",
"env": "production"
}
EventBridge から起動する際は、Configure input の Constant (JSON text) からこれを与えます。
実行結果の見方
実行結果画面では、各ステップの遷移とステータスを視覚的に確認できます。
意図どおり Job 2 でエラーとなっています。
ステータスが Caught Error となっており、エラーは捕捉され Send fail event に遷移。
そのまま State machine の最終ステータスは Fail で決着しています。

Execution event history の欄にステートの変遷と経過時間、子State machine へのリンクが並びます。

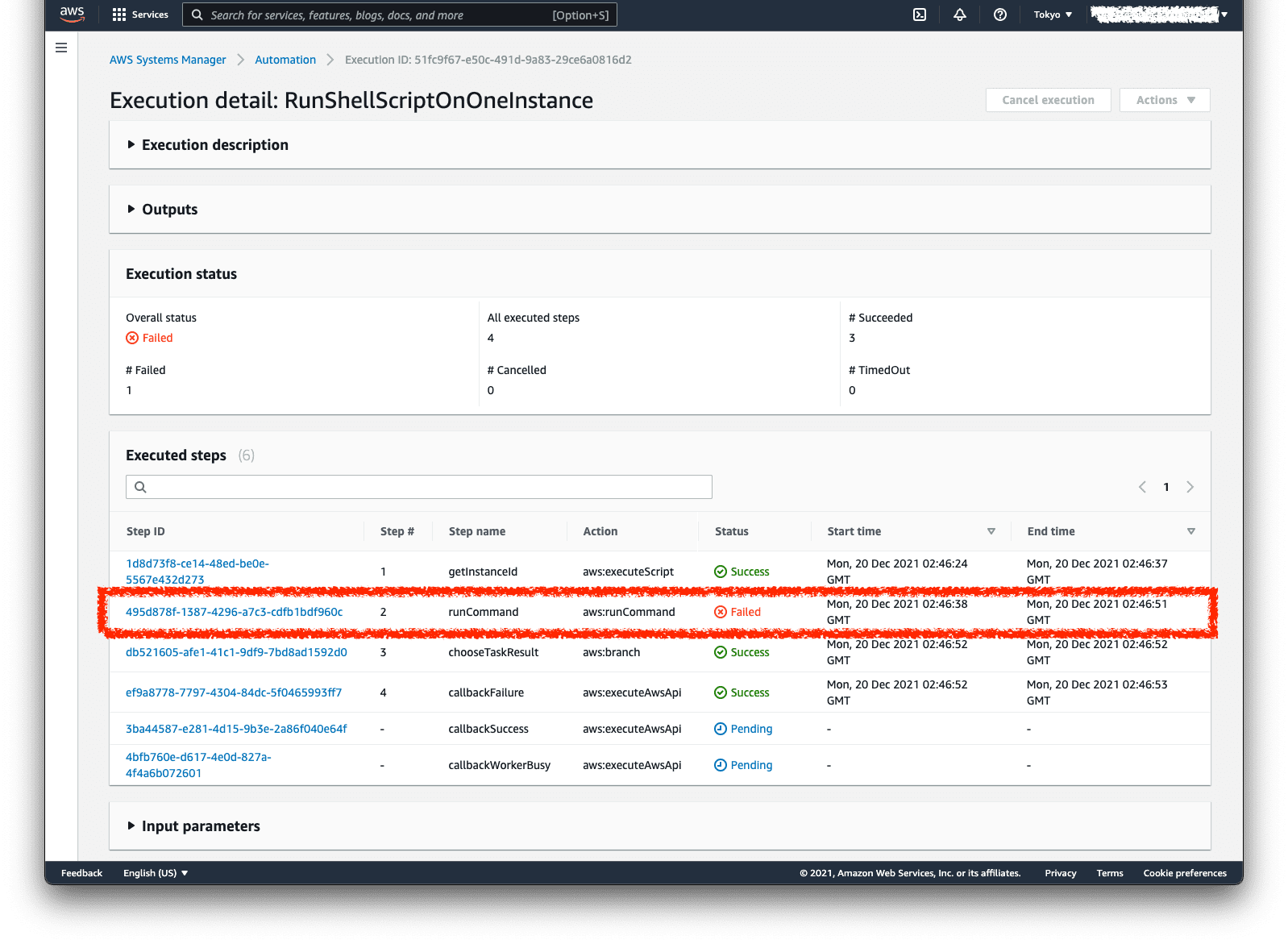
子State machine へのリンクから Job 2 の実行結果を確認してみると、System Manager Automation でエラーになっていることがわかります。

ステートの詳細から Automation の実行URL を探し、開いてみます。

ステップ #2 の runCommand が Failed なので開いてみます。
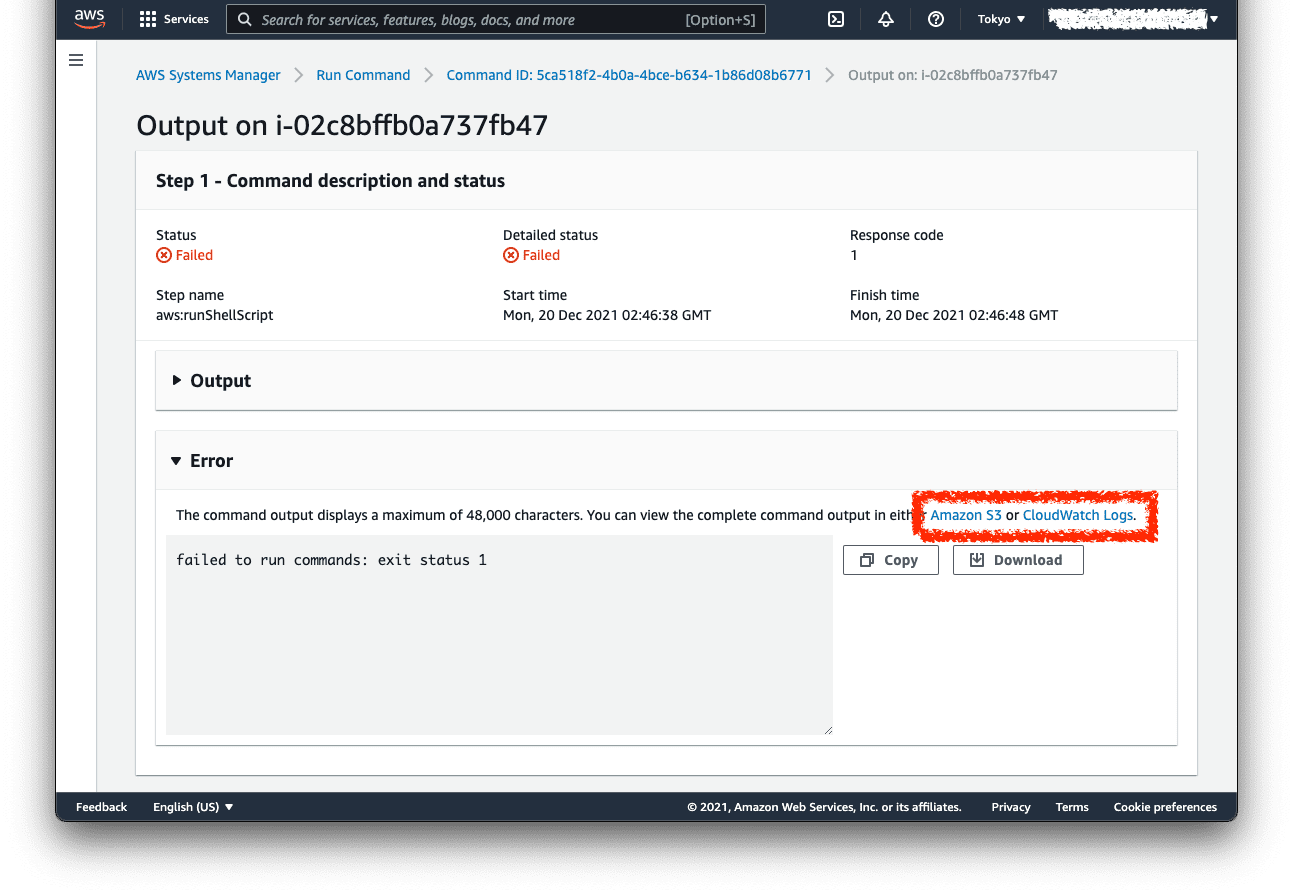
コマンドの終了ステータスや stdout/stderr を確認できます。
Run Command の実行結果へのリンクもあるので、詳細はそちらを参照するとよいでしょう。

前述 のとおり Run Command の出力には文字数制限があるので、完全なログは CloudWatch Logs や S3 で閲覧します。
(リンクがあります。)
Appendix
全ジョブ・ネットワークの俯瞰
個別のジョブ・ネットワークの状態は上記の手順で 1つ1つ見ていけばよいですが、ジョブ管理システムとしては、全ジョブ・ネットワークの状態を俯瞰的に見たいところです。
残念ながら AWS のコンソールでは難しいので自作する必要があります。
見たいのはとりあえず全ジョブ・ネットワークのステータス、実行時間、実行ノードくらいでしょうか。
以下のような画面を作成するとよいでしょう。
タイムアウト
システムのデータ量が増えればジョブの実行時間も比例して増大します。
今回の仕組みの上で、最長でどれくらい長くジョブを走らせられるのか調べてみました。
先に結論を書くと、数日にわたって実行されるジョブがある場合は System Manager Automation と Run Command に制約されそうです。
Step Functions
Step Functions は Standardタイプで 最長 1年間 です。
充分すぎるほどなので、Step Functions が問題になることはないでしょう。
System Manager Automation
ドキュメントに記述が見つからず、個々の Automation実行に上限があるのかは不明です。
ただし、関連する制約として Service Quotas で月あたりの実行時間の合計に上限がありました。
- Quota name:
- Automation execution time per month
- Description:
- Maximum seconds number of Automation executions for each AWS account and in each AWS Region per month.
- AWS default quota value:
- 30,000,000 seconds
- Adjustable:
- Yes
月あたり 30,000,000 秒 = 8,333時間ですね。
Adjustable なので、足りないようなら引き上げを申請できます。
System Manager Run Command
Run Command としての仕組み自体の上限は不明ですが、Run Commandドキュメント AWS-RunShellScript の上限は 172,800秒 (= 48時間) までです。
AWS-RunShellScript
{
"schemaVersion": "1.2",
"description": "Run a shell script or specify the commands to run.",
"parameters": {
...(略)...
"executionTimeout": {
"type": "String",
"default": "3600",
"description": "(Optional) The time in seconds for a command to complete before it is considered to have failed. Default is 3600 (1 hour). Maximum is 172800 (48 hours).",
"allowedPattern": "([1-9][0-9]{0,4})|(1[0-6][0-9]{4})|(17[0-1][0-9]{3})|(172[0-7][0-9]{2})|(172800)"
}
},
"runtimeConfig": {
"aws:runShellScript": {
"properties": [
{
"id": "0.aws:runShellScript",
"runCommand": "{{ commands }}",
"workingDirectory": "{{ workingDirectory }}",
"timeoutSeconds": "{{ executionTimeout }}"
}
]
}
}
}
allowedPattern で入力値を 0 〜 172800 に絞っているので、ドキュメントをコピーしてこの制約を取り外せば 172,800秒を超えてコマンドを実行できるかもしれません。
(未検証です。)
まとめ
AWS のマネージド・サービスを組み合わせて、cron による昔ながらのジョブ実行環境を代替してみました。
Step Functions や System Manager を利用することで、ジョブ管理システムに求める要件をうまく満たすとともに、従来の (= 製品としての重厚な) ジョブ管理システムと比較して運用負荷の低減を期待できます。
多数のジョブ状況の俯瞰が難しい点、タイムアウトの上限値が不明である点に不安がありますが、小規模な環境であれば問題なく適用できるかと思います。
今後ともよろしくお願い申し上げます。
当記事の図表には Font Awesome のアイコンを使用しています。