Webサイトに対する監視設計の実例

はじめに
平素は大変お世話になっております。
クイックガードのパー子です。
前回の記事では、URL監視の始め方についてご紹介しました。
(URL監視の始め方 - 押さえておきたいポイントと選び方の指針)
今回はもっと一般的なトピックとして、監視全般の設計の進め方について、実在のシステムを例に解説したいと思います。
弊社が運営している「ひとりインフラ」という Webサイトに対して、具体的にどのような判断で監視設計を行なったのか見ていきます。
監視設計の流れ
監視にまつわるアンチパターンとして、「監視ツールが対応しているからといって、とりあえず監視できるものをなんでも監視してしまう」という失敗をよく目にします。
どのツールも Ping監視、プロセス監視、ログ監視、ハードウェア監視… など多数の監視方式のサポートをうたっていますが、手段が用意されているからといってよく考えずにアラートをセットしても、運用性の向上に効果がないどころか「目的のわからない監視項目。意味のないアラート。」とノイズになってしまって逆効果です。
何のために監視をするのか?
言い換えると、どのような事象に備えたいのかを明確にすることが大事です。
手あたり次第に監視を入れるのではなく、そのシステムを運用していると発生し得る事象 (= 多くの場合は望まないトラブル) を、誰の立場で、どのような形で検知して、どういったアクションに繋げていきたいかを定義したうえで、それに沿うように必要十分な量だけ監視したいところです。
弊社では以下の流れで監視設計を進めます。
- 目的の定義
- 個別事象の列挙
- 対処方針の決定
- 監視方式の選定
- 閾値とパラメータの調整
- 運用体制の整備

「ひとりインフラ」のシステム構成
具体的な監視設計に入る前に、前提知識として「ひとりインフラ」のシステム構成を解説します。
「ひとりインフラ」は、主に小規模事業者のインフラご担当者様を対象とした業務支援・代行サービスで、https://hitori-infra.com/ にてサービス紹介とお問い合わせフォームを兼ねた単一ページの Webサイトを展開しています。
お問い合わせが POST されたら、弊社スタッフに通知メールが送信されるとともに、お客さまにも確認メールが送信されます。
システム構成は以下の図のとおりで、

- フォームは S3 に配置
- お問い合わせデータは API Gateway + Lambda に POST
- SES 経由でメール送信
という平凡な技術選定で構築しています。
なお、お問い合わせフォームをただ普通に実現するなら自前で作り込むことはせずに以下のようなサービスを使ったほうがよいでしょうが、弊社ではシステム管理の実験用システムとして、融通が効くようにあえて自前で実装&運用しています。
「ひとりインフラ」の監視設計
「ひとりインフラ」のシステム構成を把握できたところで、本題である監視設計の実際を見ていきます。
目的の定義
第一に、監視の目的とレベル感を定めます。
「ひとりインフラ」の Webサイトが提供する便益は主に以下2点であり、
- サービスに関する情報提供
- お問い合わせの受け付け
これら便益の提供が阻害されれば Webサイトの存在価値が毀損されます。
ゆえに我々は以下を監視の目的としました。
「上記便益を提供できない事態に陥ったこと、または、放っておけば陥る可能性が高いことを速やかに検知し、復旧/緩和行動を開始できる。」
監視のレベル感については、すでにシステム自体に SLO (= Service Level Objective) などが定められているはずですので、それに準拠すればよいでしょう。
(定められていない場合は、これを機に明文化することをオススメします!)
「ひとりインフラ」はシステム構成が簡素で動的な部分も少なく、マネージド・サービスを多用しているため、過度な監視は施さず、なるべく少ない監視項目でシステム全体の健康状態を把握できるように努めました。
個別事象の列挙
続いて、監視対象とすべき事象を具体的に考えていきます。
想像力をフルに働かせて、どのような事象が生じたら検知したいのか (= 今回の例で言えば、「ひとりインフラ」Webサイトの価値を脅かす事象は何か?) を列挙します。
思いつくまま闇雲に挙げるのではなく、システムを構成するコンポーネントの連結箇所ごとに見ていくのがコツです。
「ひとりインフラ」では以下のフローで処理が流れており、
- Webブラウザ –(1)–> CloudFront + S3
- Webブラウザ –(2)–> API Gateway –(3)–> Lambda –(4)–> SES –(5)–> 相手方SMTPサーバ
この (1) 〜 (5) について順に見ていくことにします。
CloudFront と S3 はもちろん別コンポーネントなのですが、前セクションで述べたとおり今回はそこまで厳密に監視したいわけではないので一体として扱うことにしました。
なお、今回はざっくりと大き目サイズで事象を列挙しましたが、大きな区分から小さな区分へ木構造でブレイクダウンしていけば、複雑なシステムでも抜け漏れ重複なく列挙できると思います。
(1) Webブラウザが CloudFront + S3 から静的アセットを取得する際:
| 事象 | システムへの影響 |
|---|---|
| AWS側トラブル | CloudFront/S3 のトラブルにより、エラーやタイムアウトが発生する。 |
| キャパシティ上限 | 同時アクセス数などの CloudFront/S3 のキャパシティ上限に引っかかり、エラーが発生する。 |
| EDoS攻撃 | 大量の機械的アクセスにより、高額な従量課金を請求される。 |
(2) Webブラウザが問い合わせデータを POST する際:
| 事象 | システムへの影響 |
|---|---|
| AWS側トラブル | API Gateway のトラブルにより、エラーやタイムアウトが発生する。 |
| キャパシティ上限 | 同時アクセス数やペイロード・サイズなどの API Gateway のキャパシティ上限に引っかかり、エラーが発生する。 |
| EDoS攻撃 | 大量の機械的アクセスにより、高額な従量課金を請求される。 |
| バックエンド起因 | バックエンド (= Lambda) のトラブルに引きずられて、API Gateway でもエラーやタイムアウトが発生する。 |
(3) POST された問い合わせデータを Lambda で処理する際:
| 事象 | システムへの影響 |
|---|---|
| AWS側トラブル | Lambda のトラブルにより、エラーやタイムアウトが発生する。 |
| キャパシティ上限 | 同時実行数やペイロード・サイズ、メモリ使用量などの Lambda のキャパシティ上限に引っかかり、エラーが発生する。 |
| コード不具合 | コードに不具合があり、エラーが発生する。 |
| レスポンス悪化 | コードや実行環境の変化に伴いレスポンスが悪化する。 |
| バックエンド起因 | バックエンド (= SES) のトラブルに引きずられて、Lambda でもエラーやタイムアウトが発生する。 |
(4) Lambda から SES API を叩く際:
| 事象 | システムへの影響 |
|---|---|
| AWS側トラブル | SES のトラブルにより、エラーやタイムアウトが発生する。 |
| キャパシティ上限 | 送信クォータなどの SES のキャパシティ上限に引っかかり、エラーが発生する。 |
(5) SES から相手方の SMTPサーバへメール送信する際:
| 事象 | システムへの影響 |
|---|---|
| Bounce | メールが届かない。 |
| 〃 | Bounce が頻発すると AWSアカウントを BAN される。 |
| Complaint | Complaint が頻発すると AWSアカウントを BAN される。 |
対処方針の決定
事象を列挙したら、それぞれの事象が発生した場合にどう対処するか定義します。
発生した際の影響度と発生頻度を考慮しつつ、システムの運営方針や SLO に照らして、関係者への連絡や被害の緩和、サービスの縮退または復旧などの手順を定めます。
ほとんど事象が発生しなかったり、発生したとしても影響が軽微であると見込まれる場合は、あえて監視しないという判断もあるでしょう。
なお、事象の影響度や、同じ事象でも異常の継続状況に応じて Warning、Critical のようにレベル分けして対処を変えるのが一般的ですが、「ひとりインフラ」では運用体制をシンプルに保つため、あえてレベル分けはしていません。
(検知されたすべてのインシデントに対して同一のレベル感で対処します。)
(1) Webブラウザが CloudFront + S3 から静的アセットを取得する際:
| 事象 | 検知 | 対処方針 |
|---|---|---|
| AWS側トラブル | ✓ | Webサイトの閲覧に支障が生じている場合に検知する。 具体的な対処内容は障害状況に応じてその場で都度判断する。 |
| キャパシティ上限 | 上限に引っかかるほどのアクセスがあるとは思えないので、監視しない。 | |
| EDoS攻撃 | ✓ | 限度を超える量のアクセスを検知し、アクセス元をブロックする。 |
(2) Webブラウザが問い合わせデータを POST する際:
| 事象 | 検知 | 対処方針 |
|---|---|---|
| AWS側トラブル | ✓ | 問い合わせフォームの動作に支障が生じている場合に検知する。 具体的な対処内容は障害状況に応じてその場で都度判断する。 |
| キャパシティ上限 | 上限に引っかかるほどのアクセスがあるとは思えないので、監視しない。 | |
| EDoS攻撃 | ✓ | 限度を超える量のアクセスを検知し、アクセス元をブロックする。 |
| バックエンド起因 | システム影響としては「AWS側トラブル」と同じなので、そちらとまとめる。 |
(3) POST された問い合わせデータを Lambda で処理する際:
| 事象 | 検知 | 対処方針 |
|---|---|---|
| AWS側トラブル | システムの異常は API Gateway に伝播されるので、そちらの監視に任せる。 | |
| キャパシティ上限 | ✓ | 他の監視項目でだいたいカバーできているので、ここではメモリ使用量のみ監視する。 上限に迫っている場合は値を引き上げる。 |
| コード不具合 | ✓ | エラーの発生を検知し、コードの修復やロールバックを試みる。 |
| レスポンス悪化 | ✓ | 実行時間の悪化を検知し、悪化原因の特定と排除を試みる。 |
| バックエンド起因 | 「AWS側トラブル」と同じく API Gateway に伝播されるので、そちらの監視に任せる。 |
(4) Lambda から SES API を叩く際:
| 事象 | 検知 | 対処方針 |
|---|---|---|
| AWS側トラブル | SES のトラブルは Lambda のエラー数に反映されるので、そちらの監視に任せる。 | |
| キャパシティ上限 | 上限に引っかかるほどメールが送信されるとは思えないので、監視しない。 |
(5) SES から相手方の SMTPサーバへメール送信する際:
| 事象 | 検知 | 対処方針 |
|---|---|---|
| Bounce | ✓ | Bounce率は常に低い値に保つ必要があるため、Bounce率が危険水準に達したら検知する。 ただし、問い合わせフォームで入力されたメールアドレスに送信するので、Bounce の発生自体を制御することは難しく、あくまで検知するのみに留める。 また、問題追跡のために送信ログを記録しておく。 |
| Complaint | ✓ | Bounce と同様、Complaint の発生を監視する。 |
監視方式の選定
対処方針を決めたら、次に、具体的にどのような方式で監視するかを検討します。
前セクションで定めた方針に沿ったアクションを取れるように、検知タイミングやオンコール担当者に提示する情報、検知の確実性・信頼性などを考慮しつつ、方式を決めましょう。
やろうと思えばいくらでも多くのメトリクスを監視できますが、経験上、対象を増やしてもあまり検知精度は上がりません。
その割に誤検知などで運用負荷が増すばかりなので、なるべく厳選することをオススメします。
- 監視対象となる事象が発生した際に変動する (= 相関のある) メトリクスを列挙する。
- 変動のパターンを見ながら、監視しやすい (= 誤検知のおそれが少ない変動パターンを示す) メトリクスを選定する。
ただし、メトリクスの収集自体 (= アラートの対象とはしない、オンデマンドでの状況把握を目的とした蓄積) は、ケチらずに、コストが許す限り積極的に行うべきと考えます。
(1) Webブラウザが CloudFront + S3 から静的アセットを取得する際:
| 事象 | メトリクス | 監視方式 |
|---|---|---|
| AWS側トラブル | HTTPステータス・コード、応答時間 | ヘルスチェック用の静的ページを用意し、定期的に HTTP で疎通確認する。 (※) |
| EDoS攻撃 | HTTPリクエスト数 | 単位時間あたりのリクエスト数が急増していないか監視する。 |
※ 総リクエスト数に占めるエラー比率で判断するケースも多いのですが、今回はより単純な監視方式である URL監視を採用しました。
(2) Webブラウザが問い合わせデータを POST する際:
| 事象 | メトリクス | 監視方式 |
|---|---|---|
| AWS側トラブル | HTTPステータス・コード、応答時間 | ヘルスチェック用のエンドポイントを用意し、定期的に HTTP で疎通確認する。 |
| EDoS攻撃 | HTTPリクエスト数 | 単位時間あたりのリクエスト数が急増していないか監視する。 |
(3) POST された問い合わせデータを Lambda で処理する際:
| 事象 | メトリクス | 監視方式 |
|---|---|---|
| キャパシティ上限 | メモリ使用量 | 単位時間あたりのメモリ使用量の最大値が Lambda の割り当て値に迫っていないか監視する。 |
| コード不具合 | 実行数 | 単位時間あたりの実行数のうち、エラーとなったものの比率が高い場合に検知する。 |
| レスポンス悪化 | 実行時間 | 単位時間あたりの実行時間 (95パーセンタイル) の推移を監視する。 |
(4) Lambda から SES API を叩く際:
前セクションで論じたとおり、監視しません。
(5) SES から相手方の SMTPサーバへメール送信する際:
| 事象 | メトリクス | 監視方式 |
|---|---|---|
| Bounce | Bounce率 | Bounce率が危険水準に達した場合に検知する。 |
| Complaint | Complaint率 | Bounce と同様 |
閾値とパラメータの調整
監視方式の選定に続き、アラートの閾値を設定します。
- 試行間隔:
- 監視を実行する間隔
- NG基準:
- 各試行において、どういう結果ならば監視対象が異常な状態であると判断するか
- NG回数:
- 連続する試行のうち、何回 NG になったらアラートを発報するか
併せて、タイムアウトや同時実行数などの、安定性に寄与するシステム・パラメータも調整するとよいでしょう。
(アラート閾値とシステム・パラメータはセットで決定すべきものであり、システム・パラメータの調整なしに閾値を設定しようとしても無理が生じます。)
なお、本記事の目的はあくまで監視設計の流れをご紹介することなので、閾値の具体的な値は伏せさせていただきます。
(1) Webブラウザが CloudFront + S3 から静的アセットを取得する際:
| 事象 | メトリクス | 試行間隔 | NG基準 | NG回数 |
|---|---|---|---|---|
| AWS側トラブル | HTTPステータス・コード、応答時間 | 60秒 | ステータス・コードが 200以外 or 応答時間が N ミリ秒以上 | 3/3 |
| EDoS攻撃 | HTTPリクエスト数 | 60秒 | 試行間隔あたり N リクエスト以上 | 1/1 |
「NG回数: 3/3」というのは、試行3回のうち 3回すべて NG になったら、つまり NG が 3回連続したらアラートを飛ばす、という意味です。
なので「1/1」は 1回でも NG となったら即アラートが飛びます。
調整対象のシステム・パラメータについては、CloudFront/S3周りでは特に調整が必要なものは見当たらなかったので、デフォルト設定のままとしました。
(2) Webブラウザが問い合わせデータを POST する際:
| 事象 | メトリクス | 試行間隔 | NG基準 | NG回数 |
|---|---|---|---|---|
| AWS側トラブル | HTTPステータス・コード、応答時間 | 60秒 | ステータス・コードが 200以外 or 応答時間が N ミリ秒以上 | 3/3 |
| EDoS攻撃 | HTTPリクエスト数 | 60秒 | 試行間隔あたり N リクエスト以上 | 1/1 |
API Gateway に関するシステム・パラメータは以下の方針で調整しました。
| パラメータ | 設定内容 |
|---|---|
| スロットリング | 大量の攻撃的アクセスの影響を緩和するために、大きすぎず、かつ、通常のアクセスは捌き切れる程度には少なすぎない値に。 |
| タイムアウト | 通常は数秒以内にレスポンスが完了するはずなので、それ以上はタイムアウトさせる。 |
(3) POST された問い合わせデータを Lambda で処理する際:
| 事象 | メトリクス | 試行間隔 | NG基準 | NG回数 |
|---|---|---|---|---|
| キャパシティ上限 | メモリ使用量 | 60秒 | 使用率が 90%以上 | 3/5 |
| コード不具合 | 実行数 | 60秒 | エラー率が 10%以上 | 1/1 |
| レスポンス悪化 | 実行時間 | 60秒 | 実行時間の 95パーセンタイルが N ミリ秒以上 | 3/5 |
Lambda のシステム・パラメータは以下のとおりです。
| パラメータ | 設定内容 |
|---|---|
| 同時実行数 | API Gateway のアクセス数と連動するはずなので、当該スロットリング値と同程度とした。 |
| タイムアウト | API Gateway のタイムアウト値を超えることはないので、当該値の 8割程度とした。 |
| メモリ | 今回の関数は使用量にほとんど変化がないので、平均使用率が 60〜70%程度になる値を選択した。 |
(4) Lambda から SES API を叩く際:
前述のとおり、このレイヤーでの監視は行いません。
(5) SES から相手方の SMTPサーバへメール送信する際:
| 事象 | メトリクス | 試行間隔 | NG基準 | NG回数 |
|---|---|---|---|---|
| Bounce | Bounce率 | 60秒 | 比率が 5%以上 | 1/1 |
| Complaint | Complaint率 | 60秒 | 比率が 0.1%以上 | 1/1 |
NG基準の値は AWS の推奨値 を採用しました。
SES のレイヤーでは特に調整すべきパラメータはありません。
運用体制の整備
ここまでで実際に監視ツールをセットアップできる状態になりましたが、監視設計の最後のステップとしてやるべきことが残っています。
安定して監視と付き合っていくためには、全体的な運用体制の整備が欠かせません。
具体的な項目としては、
- システムの状態把握のためのダッシュボードの整備
- オンコール体制組み
- アラート時の対応フローの策定
- 振り返りと改善フローの策定
最低限このあたりは必要になるかと思います。
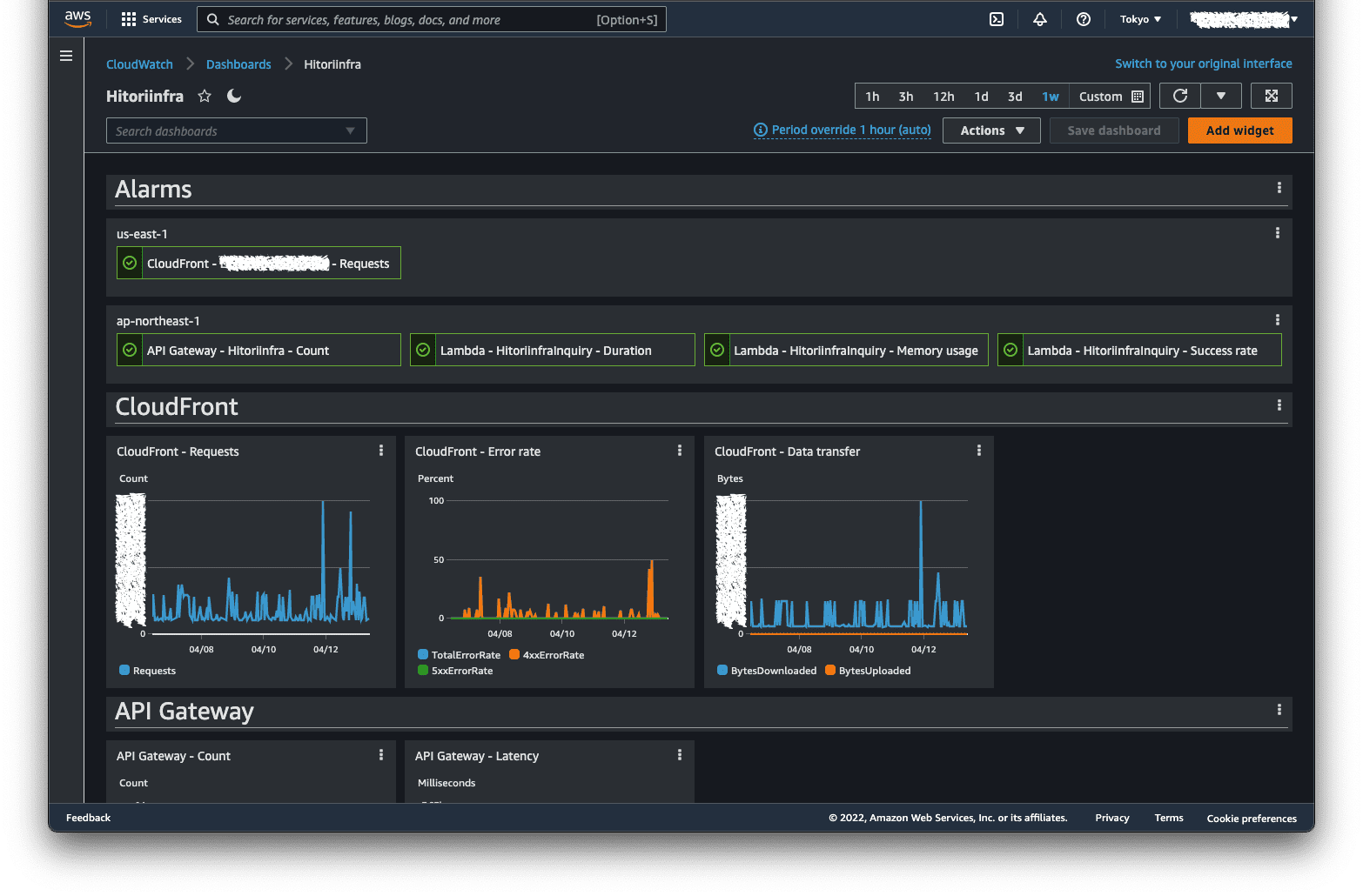
「ひとりインフラ」においては、MSP である弊社では基本的な体制はすでに整備済みのため、それに付け足す形でダッシュボード、システム構成図、対応手順書などのシステム固有の情報を具備しました。
例えばダッシュボードは CloudWatch で以下のようなものを組んでいます。
一から体制を構築する場合は Atlassian Incident Management や PagerDuty Incident Response などのガイドラインを参考にするとよいでしょう。
Appendix
監視設計書
監視しない項目も含めて一覧にまとめておくと、あとで設計の根拠を追跡できて役に立つのでオススメです。

参考書籍
監視についてもっと深く知りたい方は、以下の書籍が参考になります。
入門 監視 - モダンなモニタリングのためのデザインパターン

近年では定番の一冊です。
特に「付録C. 実践 監視 SaaS」は、SaaS に限らない監視全般のポイントがコンパクトにまとめられていて必見です。
Webエンジニアのための監視システム実装ガイド

Webサービスにまつわる監視について、必要な知識が体系的にわかりやすく書かれています。
SRE サイトリライアビリティエンジニアリング - Googleの信頼性を支えるエンジニアリングチーム

監視のみに焦点を当てた本ではありませんが、監視設計するうえで Site Reliability Engineering の考え方はとても役に立ちます。
システム運用アンチパターン - エンジニアがDevOpsで解決する組織・自動化・コミュニケーション

監視の運用に関するアンチパターン(= 「6章. アラート疲れ」や「9章. せっかくのインシデントを無駄にする」) が紹介されています。
運用体制を整備する際、同じ轍を踏まないよう参考にするとよいでしょう。
まとめ
弊社が運営する Webサイト「ひとりインフラ」に対して、どのような判断に基づいて監視設計を行なったのか実例をご紹介しました。
いきなり、かつ、闇雲に監視項目を列挙するのではなく、まず目的の定義から始めることが重要です。
また、監視ツールをセットアップして終わりではなく、その運用体制まで含めて総合的に環境を整えるようにしましょう。
「ひとりインフラ」はマネージド・サービスを活用したサーバレスなシステムですが、伝統的なオンプレミスのサーバに対する監視でも基本的な設計手順は変わりません。
ぜひ参考にしてみてください。
今後ともよろしくお願い申し上げます。
当記事の図表には Material Icons、AWS Architecture Icons を使用しています。