CloudWatch で独自メトリクス - いろんな方式を試してみた

はじめに
平素は大変お世話になっております。
クイックガードのパー子です。
CloudWatch で独自メトリクスを計測したい場合、CloudWatch API を直に扱ったり、CloudWatchエージェント の各連携機能を使うなど、いくつかの方式が考えられます。
この記事では、それらの各方式を比較し、それぞれの使い所を考察してみました。
方式の概観
独自メトリクスの計測方式を思いつくだけ列挙してみました。
以下 6つです。
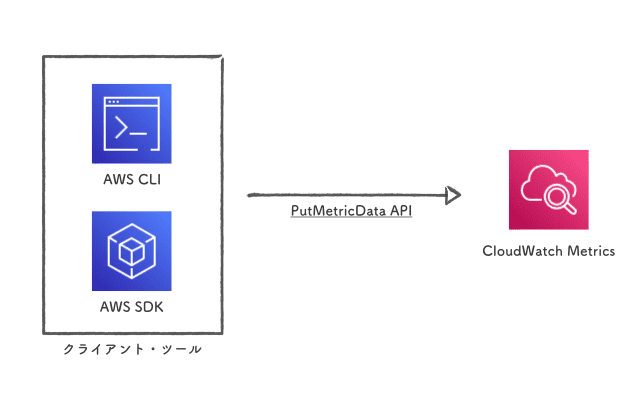
PutMetricData API
まず、CloudWatch の PutMetricData API を直接叩く、素朴な方式です。
AWS CLI や 各プログラミング言語の SDK を利用します。
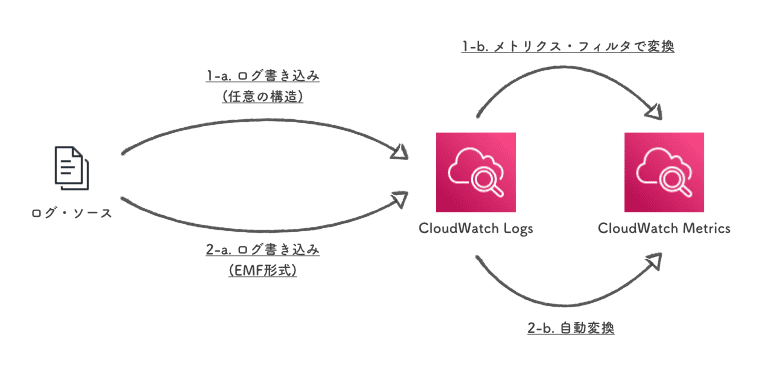
CloudWatch Logs経由
メトリクス値をいったん CloudWatch Logs にログとして格納したうえで、ログから CloudWatch Metrics に変換する方式です。
任意の構造のログ・メッセージを メトリクス・フィルタ で変換する方式と、CloudWatch Metrics に自動で変換される EMF (Embedded Metric Format) という特別な形式のメッセージを書き込む方式の 2通りがあります。
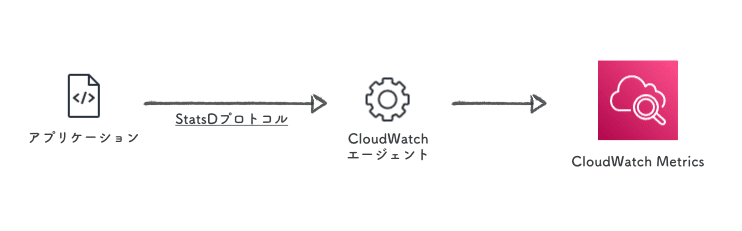
StatsD
CloudWatchエージェント を経由して StatsDプロトコル でメトリクスを送る方式です。
StatsD はアプリケーション・メトリクスの取得に使われることが多く、各プログラミング言語用のクライアント が豊富に用意されています。
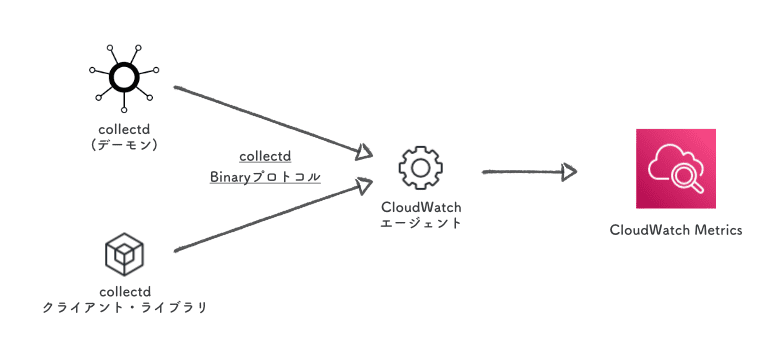
collectd
StatsD と同じく、CloudWatchエージェント に対して collectdプロトコルでメトリクスを送ります。
Networkプラグイン を用いてデーモンから転送するのが基本ですが、Binaryプロトコル を直接喋って任意のメトリクスを送ることもできます。
Prometheus
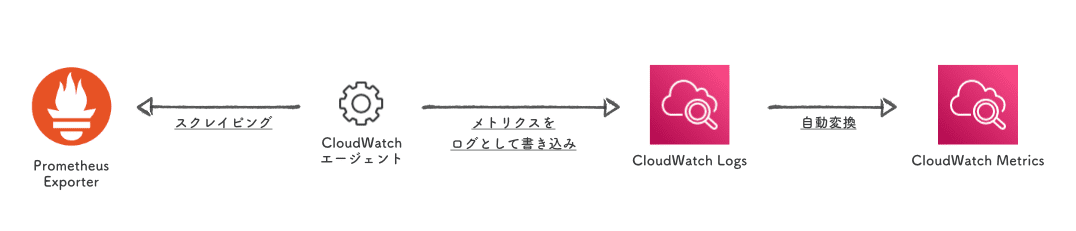
CloudWatchエージェントが Prometheus exporter をスクレイピングする方式です。
スクレイピングして取得したメトリクスは CloudWatch Logs に格納されます。
同時に EMF の設定 を記述しておくことで、指定したメトリクスが自動で CloudWatch Metrics に変換されます。
サード・パーティのエージェント
CloudWatchエージェントの代わりに、CloudWatch へのメトリクス送信をサポートしているエージェントを使う方式です。
例えば Telegraf などがあります。
ちなみに CloudWatchエージェント のコアは Telegraf だったりします。
Amazon CloudWatch Agent uses the open-source project telegraf as its dependency. It operates by starting a telegraf agent with some original plugins and some customized plugins.
やってみる
方式の概観を眺めたところで、続いて実際に各方式を 1つずつ試してみます。
計測対象のメトリクスは、単純に nginx のリクエスト数の累計とします。
リクエスト数を取得できるように、stub_statusモジュールを有効化しておきます。
/etc/nginx/default.d/stub_status.conf
location = "/status" {
stub_status;
}
PutMetricData API
この方式は直感的なので、特に難しい点はないでしょう。
AWS CLI を用いるのが簡単です。
以下のような適当なスクリプトを書いて Cron で回す、というのがよくある使い方だと思います。
put-metric-data.sh
#!/bin/bash
export AWS_DEFAULT_REGION='ap-northeast-1'
REQUESTS="$(
curl -s 'http://localhost/status' \
| grep -o -E '[0-9]+ [0-9]+ [0-9]+' \
| cut -d ' ' -f 3
)"
INSTANCE_ID="$(
curl -s 'http://169.254.169.254/latest/meta-data/instance-id'
)"
aws cloudwatch put-metric-data \
--namespace 'PutMetricDataAPI' \
--metric-name 'Requests' \
--value "${REQUESTS}" \
--unit 'Count' \
--dimensions "InstanceId=${INSTANCE_ID}"
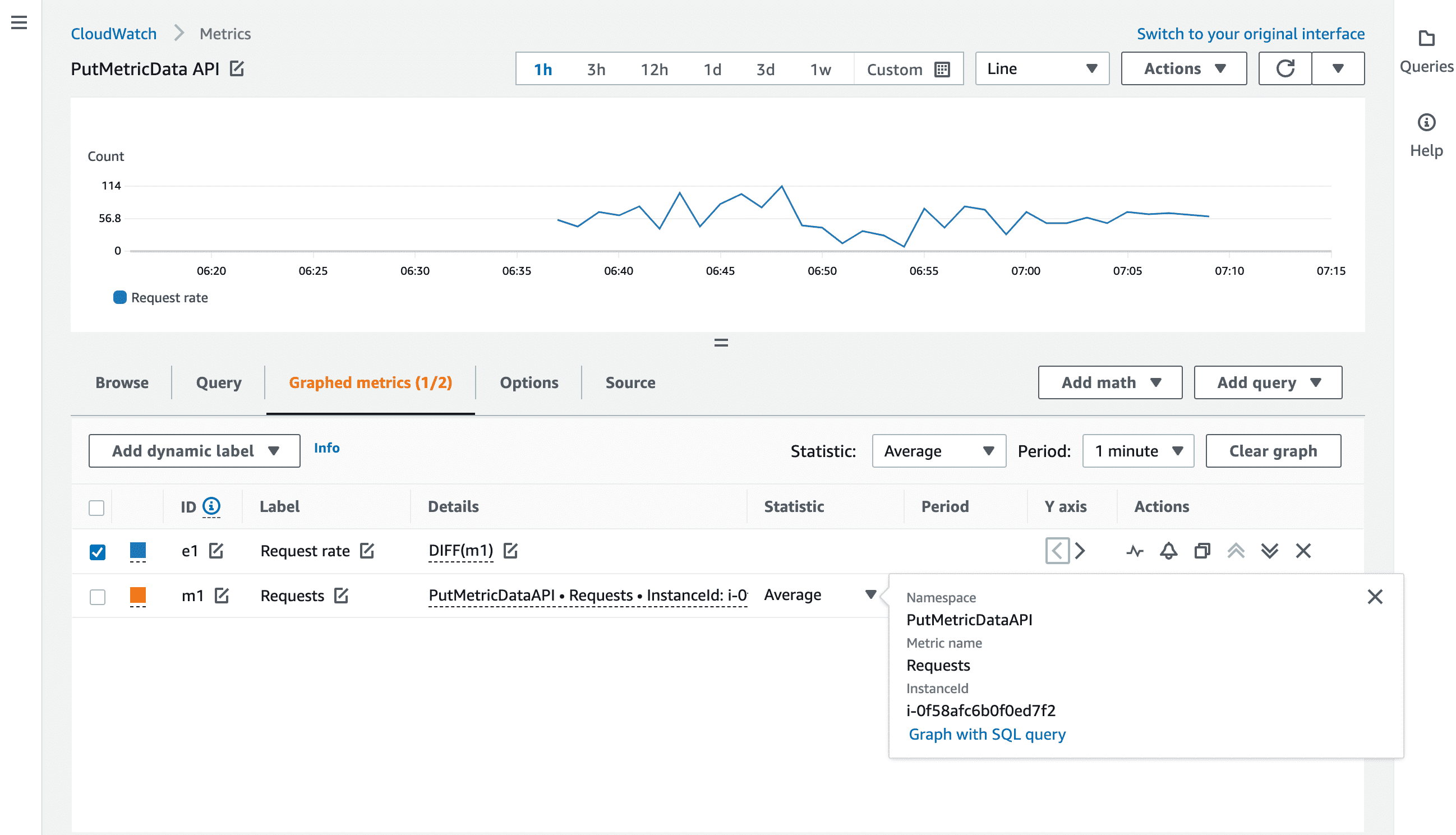
(リクエスト数を見る際、だいたいのケースで興味があるのは累積ではなく単位時間あたりの数だと思うので、DIFF() でデータ・ポイント間の差分を表示しています。)
CloudWatch Logs経由
メトリクス・フィルタ
まずはメトリクスの元となるログ・メッセージを生成します。
フィルタでは特定のパターンでパースするので、JSON などの構造化されたメッセージがよいでしょう。
put-log-events.sh
#!/bin/bash
export AWS_DEFAULT_REGION='ap-northeast-1'
REQUESTS="$(
curl -s 'http://localhost/status' \
| grep -o -E '[0-9]+ [0-9]+ [0-9]+' \
| cut -d ' ' -f 3
)"
INSTANCE_ID="$(
curl -s http://169.254.169.254/latest/meta-data/instance-id
)"
LOG_GROUP='MetricFilter'
LOG_STREAM='nginx'
NEXT_TOKEN="$(
aws logs describe-log-streams \
--log-group-name "${LOG_GROUP}" \
--query "logStreams[?logStreamName == '${LOG_STREAM}'] | [0].uploadSequenceToken" \
--output 'text'
)"
if [ "${NEXT_TOKEN}" != 'None' ]; then
HAS_NEXT_TOKEN=1
fi
aws logs put-log-events \
--log-group-name "${LOG_GROUP}" \
--log-stream-name "${LOG_STREAM}" \
--log-events timestamp=$( date '+%s%3N' ),message="$(
cat << EOS | jq '@json'
{
"type": "requests",
"instance_id": "${INSTANCE_ID}",
"value": ${REQUESTS}
}
EOS
)" \
${HAS_NEXT_TOKEN:+--sequence-token "${NEXT_TOKEN}"}
- ストリームに連続的に書き込むためには Sequence token が必要
timestampの単位はミリ秒- JSON形式のメッセージを送るために文字列化? エスケープ? する
というあたりがこのスクリプトのポイントです。
ログが溜まったらメトリクス・フィルタを設定します。
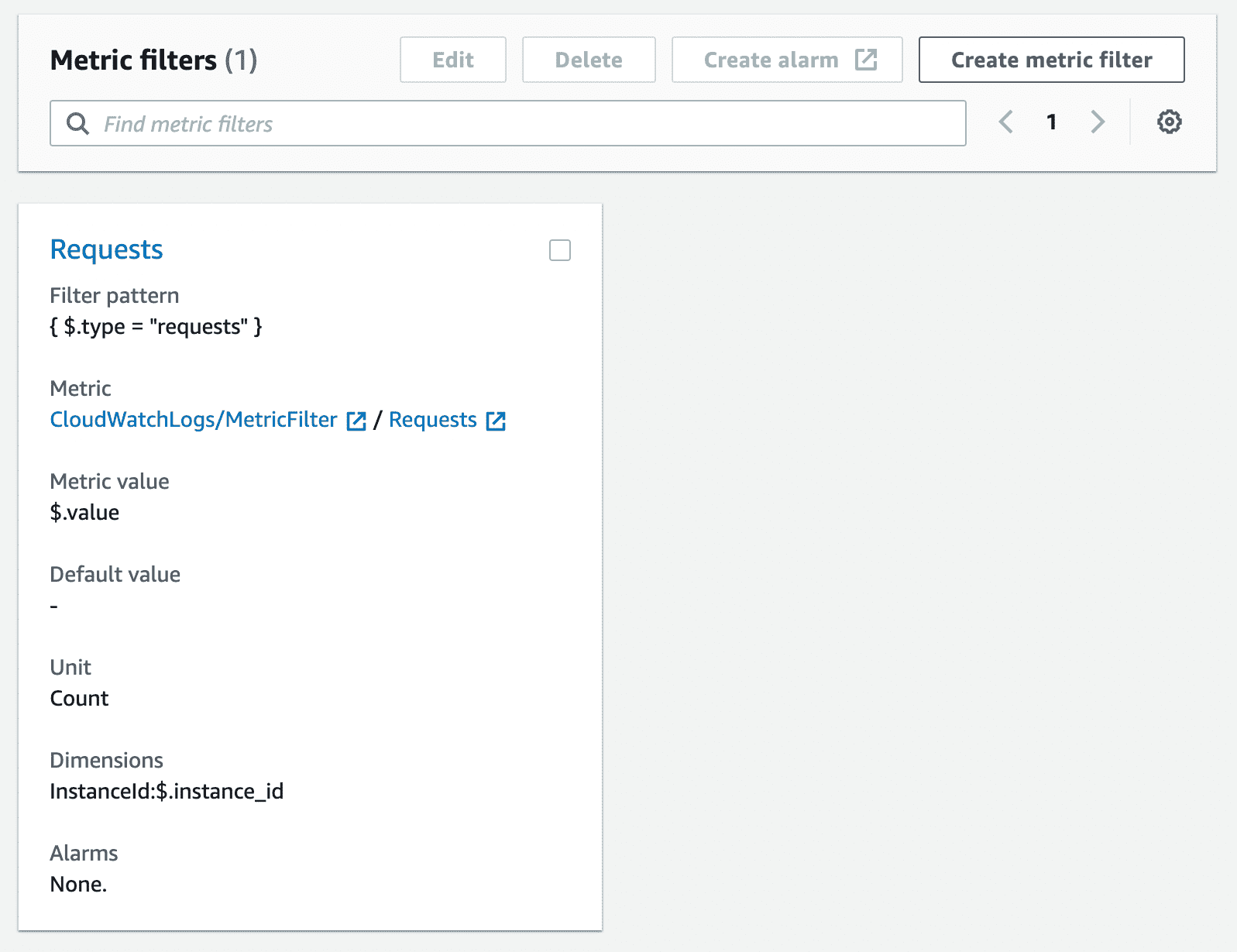
これで CloudWatch Metrics へ変換されていきます。
EMF
次は、メトリクス・フィルタを使わずに、EMF による CloudWatch Metrics への自動変換を試してみます。
EMF形式でメッセージを書き込む方法にはいくつか選択肢があり、
ここでは CloudWatchエージェント経由で書き込んでみます。
まず、CloudWatchエージェントに設定を入れます。
CloudWatchエージェント: config.json
{
"logs": {
"metrics_collected": {
"emf": {}
}
}
}
emfキーの中身が空ですが、これで OK です。
CloudWatchエージェントが udp:25888 を待ち受けるので、指定の形式 でメッセージを投げてみます。
send-emf-message.sh
#!/bin/bash
REQUESTS="$(
curl -s 'http://localhost/status' \
| grep -o -E '[0-9]+ [0-9]+ [0-9]+' \
| cut -d ' ' -f 3
)"
INSTANCE_ID="$(
curl -s http://169.254.169.254/latest/meta-data/instance-id
)"
cat << EOS | jq -c '.' > /dev/udp/127.0.0.1/25888
{
"_aws": {
"Timestamp": $( date '+%s%3N' ),
"LogGroupName": "EMF",
"CloudWatchMetrics": [
{
"Namespace": "CloudWatchLogs/EMF",
"Dimensions": [
[
"InstanceId"
]
],
"Metrics": [
{
"Name": "Requests",
"Unit": "Count"
}
]
}
]
},
"InstanceId": "${INSTANCE_ID}",
"Requests": ${REQUESTS}
}
EOS
メッセージの形式として以下の点に注意しましょう。
- CloudWatchエージェント経由で書き込む場合に限り、
LogGroupNameで書き込み先のグループを指定する - 改行 (=
\n) を含めてはならない Timestampの単位はミリ秒
このスクリプトを実行すると、指定したグループにメッセージが書き込まれ、同時に CloudWatch Metrics に変換されます。
StatsD
StatsD のプロトコルは単純で、
{{ メトリクス名 }}:{{ 値 }}|{{ タイプ }}|@{{ サンプリング・レート }}|#{{ タグ名 }}:{{ タグ値 }},{{ タグ名 }}:{{ タグ値 }},...
これを UDP で送るだけです。
メトリクスのタイプ として Counter や Gauge などがあり、これらは CloudWatch Metrics におけるディメンションとして扱われます。
また、タグも同じくディメンション扱いです。
CloudWatchエージェントの設定 は、ミニマムだと以下のとおりで、
CloudWatchエージェント: config.json
{
"metrics": {
"metrics_collected": {
"statsd": {}
}
}
}
デフォルトで udp:8125 を待ち受けます。
send-statsd-metrics.sh
#!/bin/bash
REQUESTS="$(
curl -s 'http://localhost/status' \
| grep -o -E '[0-9]+ [0-9]+ [0-9]+' \
| cut -d ' ' -f 3
)"
INSTANCE_ID="$(
curl -s http://169.254.169.254/latest/meta-data/instance-id
)"
echo "Requests:${REQUESTS}|c|#InstanceId:${INSTANCE_ID},type:StatsD" \
> /dev/udp/127.0.0.1/8125
collectd
CloudWatchエージェントが collectdプロトコルを扱えるように 設定 を入れます。
CloudWatchエージェント: config.json
{
"metrics": {
"metrics_collected": {
"collectd": {
"collectd_security_level": "none"
}
}
}
}
待ち受けアドレスを指定しない場合のデフォルトは udp:25826 です。
暗号化方式 (= collectd_security_level) は、同じインスタンス内なので none (= 暗号化も署名もしない) とします。
セキュアでない通信経路を通るなら、encrypt や sign を選択したほうがよいでしょう。
(認証用ファイルは collectd_auth_file で指定します。)
デーモン
Amazon Linux2 なら amazon-linux-extras で collectd をインストールできます。
併せて、nginx のメトリクスを取得するためにプラグインもインストールします。
$ sudo amazon-linux-extras install collectd
$ sudo yum install collectd-nginx
nginxプラグインの設定ファイルは /etc/collectd.d/nginx.conf に配置されます。
stub_status の URL を指定します。
/etc/collectd.d/nginx.conf
LoadPlugin "nginx"
<Plugin "nginx">
URL "http://localhost/status"
</Plugin>
続いて、CloudWatchエージェントにメトリクスを送るために Networkプラグインを有効化します。
/etc/collectd.d/network.conf というファイルを以下の内容で作成します。
/etc/collectd.d/network.conf
LoadPlugin "network"
<Plugin "network">
Server "localhost"
</Plugin>
Server "Host" [Port] という形式で 送信先を指定 できますが、ポートを省略した場合は udp:25826 がデフォルトです。
(これは CloudWatchエージェントのデフォルトの待ち受けポートと同じです。)
暗号化 or 署名してメトリクスを送るなら、認証周り を設定しましょう。
collectd を起動すれば、collectd が取得したメトリクスがすべて CloudWatch Metrics に転送されます。
なお、Chains という機能を使うことで、CloudWatch Metrics へ送るメトリクスを絞り込むことができます。
例として、FQDN ではないホストから収集したメトリクスを除外するルールは、RegEx match を使って以下のように書けます。
/etc/collectd.d/filter.conf
LoadPlugin "match_regex"
<Chain "PreCache">
<Rule "ignore_non_fqdn">
<Match "regex">
Host "^[^\\.]*$"
Invert false
</Match>
Target "stop"
</Rule>
</Chain>
転送間隔は デフォルトで 10秒 なので、CloudWatch Metrics側の Sample Count は 1分間に 6回となります。
この間隔は Intervalディレクティブ で変更できます。
Interval 60
また、CloudWatch Metrics に送る際、デフォルトではメトリクス名の頭に collectd_ というプレフィックスが付与されます。
変更したい場合は CloudWatchエージェントの設定項目 name_prefix で任意のプレフィックスを指定できます。
Binaryプロトコル
デーモン経由ではなく、生のプロトコルを直接喋って単一のメトリクスを CloudWatchエージェントに送ることもできます。
プロトコルの仕様は 公式ドキュメント に記載されていますが、自前で実装するのは面倒なので 既成のクライアント・ライブラリ を使用します。
今回は Golang用のライブラリ を使うことにします。
クライアントの実装は collectd.org/networkパッケージの network.Client です。
collectd.go
package main
import (
"context"
"log"
"net"
"os"
"strconv"
"time"
"collectd.org/api"
"collectd.org/exec"
"collectd.org/network"
)
func main() {
ctx := context.Background()
conn, err := network.Dial(net.JoinHostPort("localhost", network.DefaultService), network.ClientOptions{})
if err != nil {
log.Fatal(err)
}
defer conn.Close()
value, _ := strconv.ParseFloat(os.Args[1], 64)
vl := api.ValueList{
Identifier: api.Identifier{
Host: exec.Hostname(),
Plugin: "golang_nginx",
Type: "nginx_requests",
},
Time: time.Now(),
Interval: exec.Interval(),
Values: []api.Value{api.Gauge(value)},
}
if err := conn.Write(ctx, &vl); err != nil {
log.Fatal(err)
}
}
api.ValueList{} で、送信するメトリクスを組み立てます。
メトリクス名やディメンションは api.Identifier{} で指定します。
| 項目名 | 意味 | 備考 | CloudWatch Metrics側の扱い |
|---|---|---|---|
| Host | 送信元ホスト名 | - | ディメンション: host |
| Plugin | このメトリクスを生成したプラグイン名 | 好きな名前を自由に名乗ってよい。 | メトリクス名の一部 (※) |
| Type | メトリクスのタイプ | types.db の中から選ぶ。 | ディメンション: type |
※ メトリクス名: {{ CloudWatchエージェントによるプレフィックス }}_{{ プラグイン名 }}_value
他にも PluginInstance や TypeInstance といったサブカテゴリ的な パラメータ を指定できます。
なお、メトリクスの形式 には GAUGE / DERIVE / COUNTER / ABSOLUTE の 4種類がありますが、HTTPリクエスト累計数の表現として妥当な形式が見当たらなかったので致し方なく GAUGE としました。
(COUNTER はカウンタの現在値ではなく DERIVE の亜種。ABSOLUTE は読み出しごとに 0 にリセットされる特殊カウンタ用。)
send-collectd-metrics.sh
#!/bin/bash
REQUESTS="$(
curl -s 'http://localhost/status' \
| grep -o -E '[0-9]+ [0-9]+ [0-9]+' \
| cut -d ' ' -f 3
)"
COLLECTD_INTERVAL=10 go run ./collectd.go ${REQUESTS}
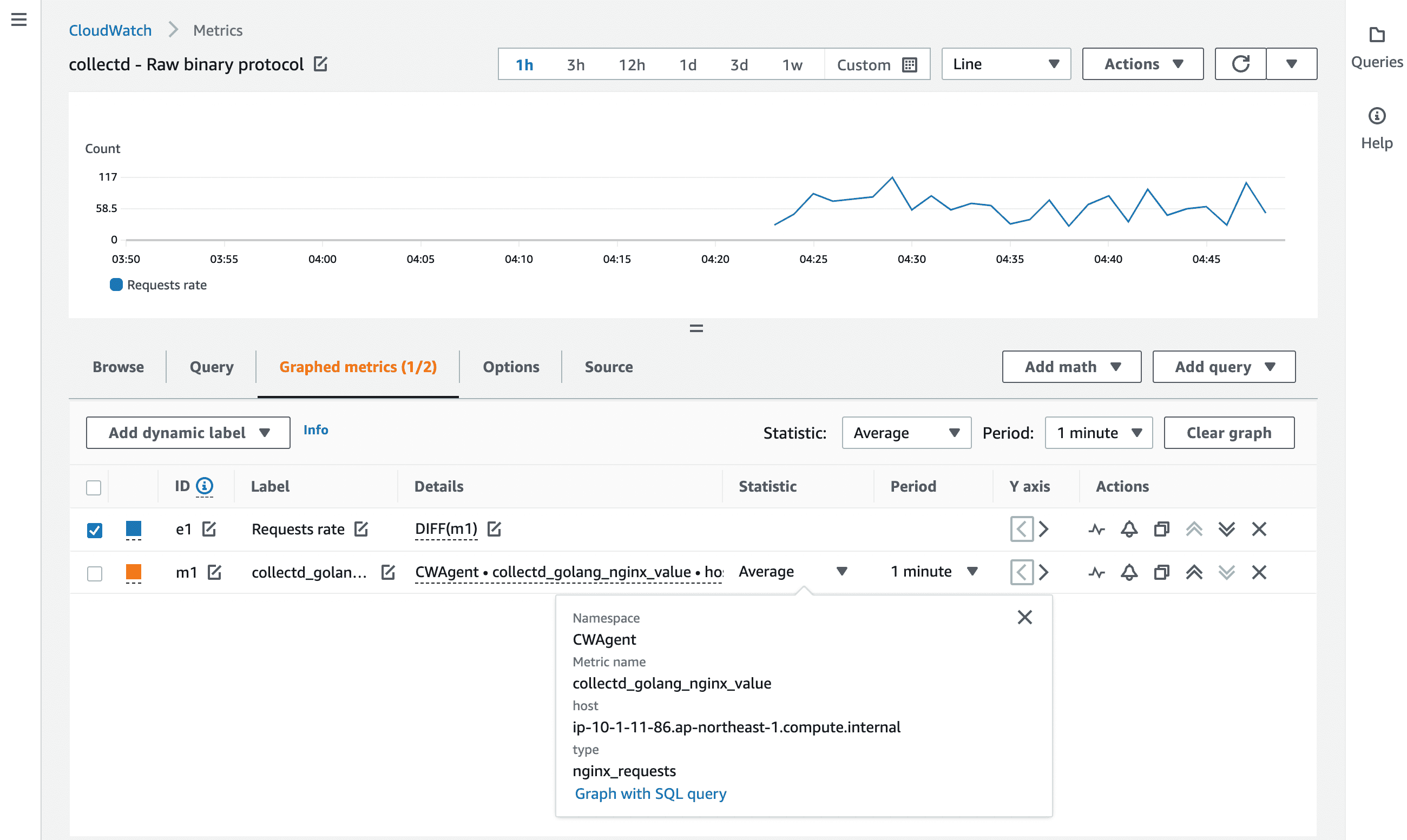
Netcat などで udp:25826 を待ち受けたうえで上記のスクリプトを実行すると、UDPパケットをキャッチできます。
パケットの中身は以下のようになっており、
00000000: 0000 0032 6970 2d31 302d 312d 3131 2d38 ...2ip-10-1-11-8
00000010: 362e 6170 2d6e 6f72 7468 6561 7374 2d31 6.ap-northeast-1
00000020: 2e63 6f6d 7075 7465 2e69 6e74 6572 6e61 .compute.interna
00000030: 6c00 0002 0011 676f 6c61 6e67 5f6e 6769 l.....golang_ngi
00000040: 6e78 0000 0400 136e 6769 6e78 5f72 6571 nx.....nginx_req
00000050: 7565 7374 7300 0008 000c 18c7 fcf8 a36e uests..........n
00000060: efa4 0009 000c 0000 0002 8000 0000 0006 ................
00000070: 000f 0001 0100 0000 0000 cbc0 40 ............@
公式ドキュメントの仕様どおり、<PartType><PartLength><Payload> という形式で Host、Plugin、Typeなどが詰まっていることを確認できます。
Prometheus
まずは Prometheus を整えます。
HTTPリクエスト数を取得するため、NGINX Prometheus Exporter を立ち上げます。
$ nginx-prometheus-exporter -nginx.scrape-uri='http://localhost/status'
/etc/prometheus.yml
global:
scrape_interval: '15s'
scrape_configs:
- job_name: 'nginx_prometheus_exporter'
static_configs:
- targets:
- 'localhost:9113'
続いて CloudWatchエージェントを 設定 します。
今は EMF の設定は後回しにして、まずは Prometheus のメトリクスを CloudWatch Logs に取り込んでみます。
CloudWatchエージェント: config.json
{
"logs": {
"metrics_collected": {
"prometheus": {
"log_group_name": "Prometheus",
"prometheus_config_path": "/etc/prometheus.yml"
}
}
}
}
CloudWatchエージェントを起動すると、CloudWatch Logs にログが格納されます。
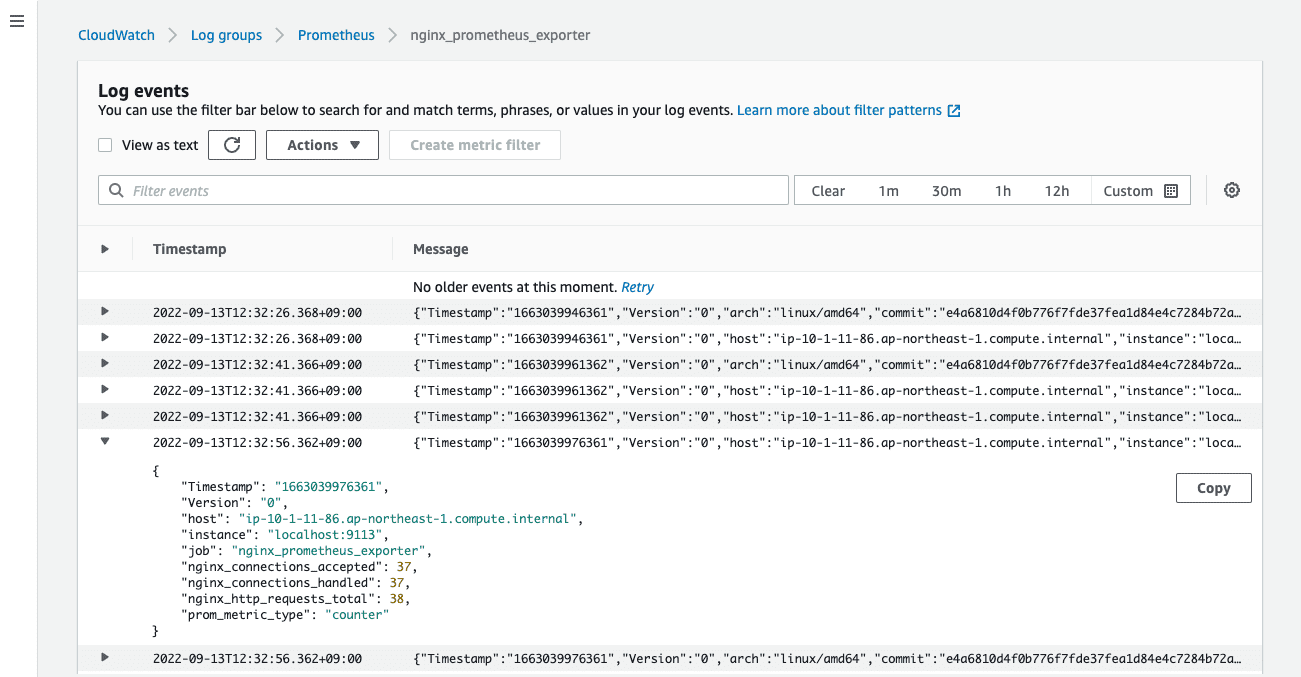
これだけではただログとして溜まるだけなので、さらに emf_processor を追加して CloudWatch Metrics へ自動変換されるようにします。
CloudWatchエージェント: config.json
{
"logs": {
"metrics_collected": {
"prometheus": {
"log_group_name": "Prometheus",
"prometheus_config_path": "/etc/prometheus.yml",
"emf_processor": {
"metric_namespace": "Prometheus",
"metric_declaration": [
{
"source_labels": [
"job"
],
"label_matcher": "^nginx_prometheus_exporter$",
"metric_selectors": [
"^nginx_http_requests_total$"
],
"dimensions": [
[
"host"
]
]
}
],
"metric_unit": {
"nginx_http_requests_total": "Count"
}
}
}
}
}
}
これで、ラベル job=~"^nginx_prometheus_exporter$" にマッチする Prometheusメトリクス nginx_http_requests_total が自動で CloudWatch Metrics へ変換されるようになります。
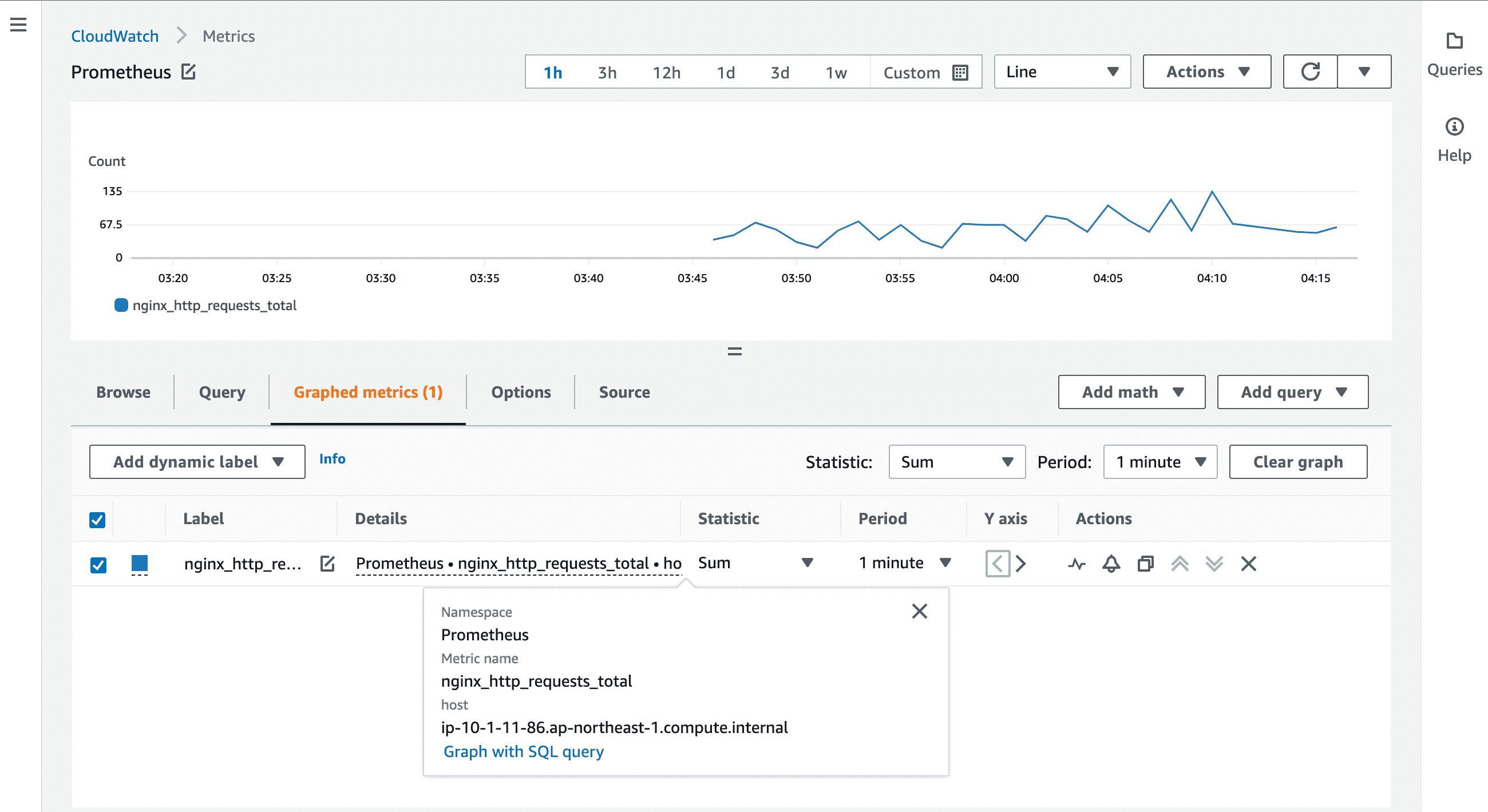
サード・パーティのエージェント
サード・パーティのエージェントにもいろいろありますが、今回は Telegraf を試してみます。
Telegraf はプラグイン方式のエージェントであり、それぞれのメトリクス収集元や転送先に合わせてプラグインを選択&設定する必要があります。
HTTPリクエスト数の取得には Nginx Input Plugin を、CloudWatch Metrics への送信のために Amazon CloudWatch Output Plugin を使います。
Nginx Input Plugin の設定では stub_status の URL を指定します。
/etc/telegraf/telegraf.d/nginx.conf
[[inputs.nginx]]
urls = ["http://localhost/status"]
Amazon CloudWatch Output Plugin ではリージョンと名前空間を設定します。
また、HTTPリクエスト数だけ選択的に CloudWatch Metircs へ送るように フィルタリング設定 を入れておきます。
/etc/telegraf/telegraf.d/cloudwatch.conf
[[outputs.cloudwatch]]
region = "ap-northeast-1"
namespace = "InfluxData/Telegraf"
namepass = ["nginx"]
fieldpass = ["requests"]
AWSクレデンシャル については、以下のとおり Telegraf がいい感じで探索してくれます。
This plugin uses a credential chain for Authentication with the CloudWatch API endpoint. In the following order the plugin will attempt to authenticate.
- Web identity provider credentials via STS if
role_arnandweb_identity_token_fileare specified- Assumed credentials via STS if
role_arnattribute is specified (source credentials are evaluated from subsequent rules)- Explicit credentials from
access_key,secret_key, andtokenattributes- Shared profile from
profileattribute- Environment Variables
- Shared Credentials
- EC2 Instance Profile
(いくつかリンク切れになっているようです。)
今回は EC2インスタンス上で動かすので EC2 Instance Profile を使うことにします。
インスタンスに cloudwatch:PutMetricData を持つ IAMロールをアタッチすれば OK です。
これで Telegraf のメトリクス取得インターバルごとに CloudWatch Metrics へ送信されます。
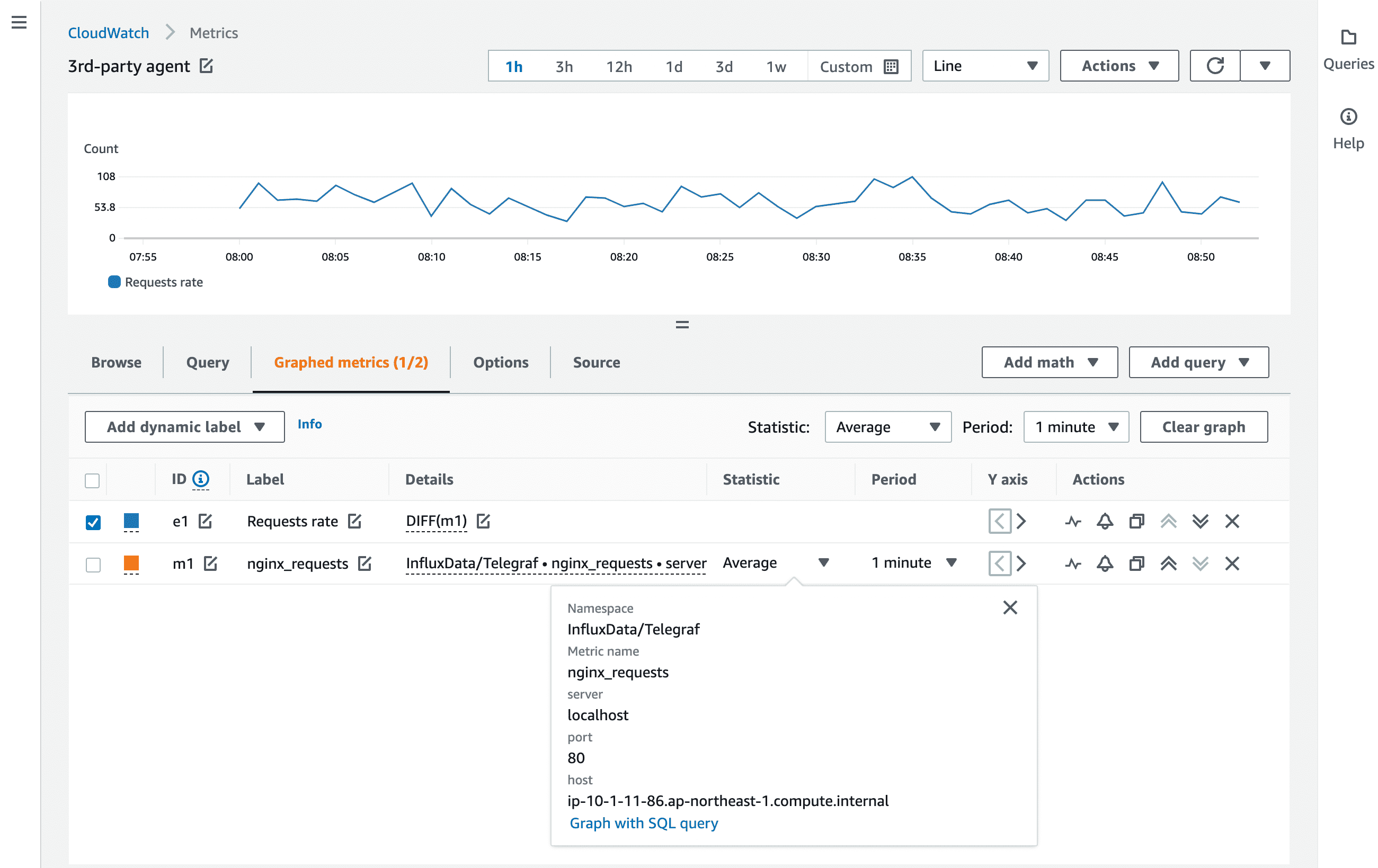
評価
最後に、簡単ですが各方式の所感や評価、使い所をまとめました。
PutMetricData API
プリミティブな API を直接実行するので、送信するメトリクスの選択や送信インターバルなど、自分の都合に合わせた仕組みを最も柔軟に構築できます。
その反面、メトリクスの収集から CloudWatch への送信まですべて自分で実装する必要があるので、大規模な運用には向きません。
いくつかのメトリクスをシュッと気軽に収集したい… という場合に採用したい方式です。
CloudWatch Logs経由
CloudWatchエージェントや Fluent Bit などによるログ収集基盤が整っているならば、規定の構造でログを吐くだけなのでお手軽です。
また、メトリクスがログとして保持されるので、問題が生じた際にあとから遡って、ログに記録された正確な値を元に調査できる点も強みです。
なお、Fluent Bit は Amazon CloudWatch output plugin が EMF をサポートしているものの、対象のメトリクスが限られるため、基本的にメトリクス・フィルタ方式を採用するとよいでしょう。
Note: Right now, only
cpuandmemmetrics can be sent to CloudWatch.
StatsD
StatsD はクライアント・ライブラリが豊富なので、アプリケーション・レベルのメトリクス収集に適しています。
ネットワーク通信にまつわる面倒ごとは CloudWatchエージェントが肩代わりしてくれるため、アプリケーションは安定してメトリクスを送ることができます。
一方、アプリケーションへの組み込み以外の領域では StatsD の存在感は薄いため、ミドルウェアやインフラ方面のメトリクス収集には別の方式を採用したほうがよいでしょう。
collectd
collectd はサーバ・メトリクスの収集に強みがあります。
多数の プラグイン が用意されており、規定のメトリクスをサクッと収集したい場合に採用したいです。
ただし、特殊なメトリクスを取得するために自前でコーディングする (= Binaryプロトコルを喋る) のはオススメしません。
別の方式を選んだほうが簡単です。
Prometheus
Prometheus をメインの監視基盤として運用している環境は多いと思います。
AWS との連携を容易にするために一部のメトリクスを CloudWatch Metrics と同期する… というケースでこの方式が有用です。
ただし、EMF のルールを細かく記述しないといけない点が面倒です。
サード・パーティのエージェント
エージェントが監視要件に合っていれば他のツールは不要なので、最も利便性があるのはこの方式かもしれません。
使い慣れたエージェントがあるならば優先的に採用したい方式です。
まとめ
CloudWatch における独自メトリクスの計測方式について、可能な方式を列挙し、実際にそれぞれ動作させてみました。
各方式の特徴を知り、適切な使い所を見極める一助になれば幸いです。
今後ともよろしくお願い申し上げます。
当記事の図表には collectd のロゴ、CNCF Logos を使用しています。